大语言模型工程师手册 从概念到生产实践 生成式大模型LLM提示工程师RAG微调大模型开发deepseek
¥74.90
| 运费: | ¥ 0.00-20.00 |




商品详情
书名:大语言模型工程师手册:从概念到生产实践
定价:99.8
ISBN:9787115667373
作者:[罗]保罗·尤斯廷(Paul Iusztin) [英]马克西姆·拉博纳(Maxime Labonne)
版次:第1版
出版时间:2025-05
内容提要:
AI技术已取得飞速发展,而大语言模型(LLM)正在*这场技术革命。本书基于MLOps*实践,提供了在实际场景中设计、训练和部署LLM的原理与实践内容。本书将指导读者构建一个兼具成本效益、可扩展且模块化的LLM Twin系统,突破传统Jupyter Notebook演示的局限,着重讲解如何构建生产级的端到端LLM系统。 本书涵盖数据工程、有监督微调和部署的相关知识,通过手把手地带领读者构建LLM Twin项目,帮助读者将MLOps的原则和组件应用于实际项目。同时,本书还涉及推理优化、偏好对齐和实时数据处理等进阶内容,是那些希望在项目中应用LLM的读者的重要学习资源。 阅读本书,读者将熟练掌握如何部署强大的LLM—既能解决实际问题,又能具备低延迟和高可用的推理能力。无论是AI领域的新手还是经验丰富的从业者,本书提供的深入的理论知识和实用的技巧,*将加深读者对LLM的理解,并提升读者在真实场景中应用它们的能力。
作者简介:
作者简介 保罗·尤斯廷(Paul Iusztin),*机器学习工程师,在生成式 AI、计算机视觉和 MLOps 领域拥有* 7 年的实战经验。曾在 Metaphysic 担任核心工程师,专注于将大型神经网络推向生产环境。 马克西姆·拉博纳(Maxime Labonne)Liquid AI 的后训练负责人,拥有巴黎理工学院机器学习博士学位,并获得谷歌人工智能与机器学习领域(AI / ML)**认证。作为开源社区的活跃贡献者,在 GitHub 上开设了LLM 课程,开发了 LLM Aut 译者简介 孟凡杰,腾讯云技术*,腾讯云原生调度技术负责人,云原生基金会大使,致力于将 AI 技术与云原生技术相结合,探索资源调度的*解决方案。 方佳瑞,清华大学计算机系博士,曾任腾讯云技术*。在机器学习、分布式系统和高性能计算等领域具有丰富的从业经验。
目录:
第 1章 理解LLM Twin的概念与架构 1
1.1 理解LLM Twin的概念 1
1.1.1 什么是LLM Twin 2
1.1.2 为什么构建LLM Twin 3
1.1.3 为什么不使用ChatGPT(或其他类似的聊天机器人) 4
1.2 规划LLM Twin的MVP 5
1.2.1 什么是MVP 5
1.2.2 定义LLM Twin的MVP 5
1.3 基于特征、训练和推理流水线构建机器学习系统 6
1.3.1 构建生产级机器学习系统的挑战 6
1.3.2 以往解决方案的问题 8
1.3.3 解决方案:机器学习系统的流水线 10
1.3.4 FTI流水线的优势 11
1.4 设计LLM Twin的系统架构 12
1.4.1 列出LLM Twin架构的技术细节 12
1.4.2 使用FTI流水线设计LLM Twin架构 13
1.4.3 关于FTI流水线架构和LLM Twin架构的*终思考 17
1.5 小结 18
第 2章 工具与安装 19
2.1 Python生态环境与项目安装 20
2.1.1 Poetry:Python项目依赖与环境管理利器 21
2.1.2 Poe the Poet:Python 项目任务管理* 22
2.2 MLOps与MLOps工具生态 23
2.2.1 Hugging Face:模型仓库 23
2.2.2 ZenML:编排、工件和元数据 24
2.2.3 Comet ML:实验跟踪工具 33
2.2.4 Opik:提示监控 34
2.3 用于存储NoSQL和向量数据的数据库 35
2.3.1 MongoDB:NoSQL数据库 35
2.3.2 Qdrant:向量数据库 35
2.4 为AWS做准备 36
2.4.1 设置AWS账户、访问密钥和CLI 36
2.4.2 SageMaker:训练与推理计算 37
2.5 小结 39
第3章 数据工程 40
3.1 设计LLM Twin的数据采集流水线 41
3.1.1 实现LLM Twin数据采集流水线 44
3.1.2 ZenML流水线及其步骤 44
3.1.3 分发器:实例化正确的爬虫 48
3.1.4 爬虫 50
3.1.5 NoSQL数据仓库文档 59
3.2 采集原始数据并存储到数据仓库 67
3.3 小结 71
第4章 RAG特征流水线 73
4.1 理解RAG 73
4.1.1 为什么使用RAG 74
4.1.2 基础RAG框架 75
4.1.3 什么是嵌入 78
4.1.4 关于向量数据库的更多内容 84
4.2 *RAG技术概览 86
4.2.1 预检索 87
4.2.2 检索 90
4.2.3 后检索 91
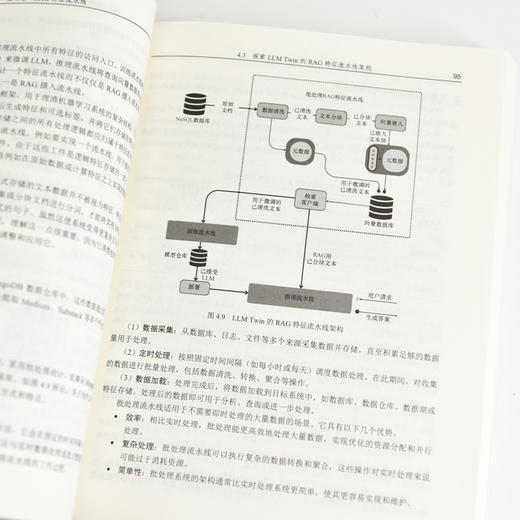
4.3 探索LLM Twin的RAG特征流水线架构 93
4.3.1 待解决的问题 93
4.3.2 特征存储 94
4.3.3 原始数据从何而来 94
4.3.4 设计RAG特征流水线架构 94
4.4 实现LLM Twin的RAG特征流水线 101
4.4.1 配置管理 101
4.4.2 ZenML流水线与步骤 102
4.4.3 Pydantic领域实体 109
4.4.4 分发器层 116
4.4.5 处理器 117
4.5 小结 125
第5章 监督微调 127
5.1 构建指令训练数据集 127
5.1.1 构建指令数据集的通用框架 128
5.1.2 数据管理 130
5.1.3 基于规则的过滤 131
5.1.4 数据去重 132
5.1.5 数据净化 133
5.1.6 数据质量评估 133
5.1.7 数据探索 136
5.1.8 数据生成 138
5.1.9 数据增强 139
5.2 构建自定义指令数据集 140
5.3 探索SFT及其关键技术 148
5.3.1 何时进行微调 148
5.3.2 指令数据集格式 149
5.3.3 聊天模板 150
5.3.4 参数*微调技术 151
5.3.5 训练参数 155
5.4 微调技术实践 158
5.5 小结 164
第6章 偏好对齐微调 165
6.1 理解偏好数据集 165
6.1.1 偏好数据 166
6.1.2 数据生成与评估 168
6.2 构建个性化偏好数据集 171
6.3 偏好对齐 177
6.3.1 基于人类反馈的强化学习 178
6.3.2 DPO 179
6.4 实践DPO 181
6.5 小结 187
第7章 LLM的评估方法 188
7.1 模型能力评估 188
7.1.1 机器学习与LLM评估的对比 188
7.1.2 通用LLM评估 189
7.1.3 领域特定LLM评估 191
7.1.4 任务特定LLM评估 193
7.2 RAG系统的评估 195
7.2.1 Ragas 196
7.2.2 ARES 197
7.3 TwinLlama-3.1-8B模型评估 198
7.3.1 生成答案 199
7.3.2 答案评估 200
7.3.3 结果分析 204
7.4 小结 207
第8章 模型推理性能优化 208
8.1 模型优化方法 208
8.1.1 KV cache 209
8.1.2 连续批处理 211
8.1.3 投机解码 212
8.1.4 优化的注意力机制 214
8.2 模型并行化 215
8.2.1 数据并行 215
8.2.2 流水线并行 216
8.2.3 张量并行 217
8.2.4 组合使用并行化方法 218
8.3 模型量化 219
8.3.1 量化简介 219
8.3.2 基于GGUF和llama.cpp的模型量化 223
8.3.3 GPTQ和EXL2量化技术 225
8.3.4 其他量化技术 226
8.4 小结 227
第9章 RAG推理流水线 228
9.1 理解LLM Twin的RAG推理流水线 229
9.2 探索LLM Twin的*RAG技术 230
9.2.1 *RAG预检索优化:查询扩展与自查询 233
9.2.2 *RAG检索优化:过滤向量搜索 239
9.2.3 *RAG后检索优化:重排序 240
9.3 构建基于RAG的LLM Twin推理流水线 243
9.3.1 实现检索模块 243
9.3.2 整合RAG推理流水线 249
9.4 小结 254
第 10章 推理流水线部署 255
10.1 部署方案的选择 256
10.1.1 吞吐量和延迟 256
10.1.2 数据 256
10.1.3 基础设施 257
10.2 深入理解推理部署方案 258
10.2.1 在线实时推理 259
10.2.2 异步推理 260
10.2.3 离线批量转换 260
10.3 模型服务的单体架构与微服务架构 261
10.3.1 单体架构 261
10.3.2 微服务架构 262
10.3.3 单体架构与微服务架构的 选择 264
10.4 探索LLM Twin的推理流水线部署 方案 265
10.5 部署LLM Twin服务 268
10.5.1 基于AWS SageMaker构建LLM 微服务 268
10.5.2 使用FastAPI构建业务 微服务 282
10.6 自动缩放应对突发流量高峰 285
10.6.1 注册缩放目标 287
10.6.2 创建弹性缩放策略 287
10.6.3 缩放限制的上下限设置 288
10.7 小结 289
第 11章 MLOps与LLMOps 290
11.1 LLMOps发展之路:从DevOps和 MLOps寻根 291
11.1.1 DevOps 291
11.1.2 MLOps 293
11.1.3 LLMOps 296
11.2 将LLM Twin流水线部署到云端 299
11.2.1 理解基础架构 300
11.2.2 MongoDB环境配置 301
11.2.3 Qdrant环境配置 302
11.2.4 设置ZenML云环境 303
11.3 为LLM Twin添加LLMOps 313
11.3.1 LLM Twin的CI/CD流水线 工作流程 313
11.3.2 GitHub Actions快速概览 316
11.3.3 CI流水线 316
11.3.4 CD流水线 320
11.3.5 测试CI/CD流水线 322
11.3.6 CT流水线 323
11.3.7 提示监控 327
11.3.8 告警 332
11.4 小结 332
附录 MLOps原则 334
定价:99.8
ISBN:9787115667373
作者:[罗]保罗·尤斯廷(Paul Iusztin) [英]马克西姆·拉博纳(Maxime Labonne)
版次:第1版
出版时间:2025-05
内容提要:
AI技术已取得飞速发展,而大语言模型(LLM)正在*这场技术革命。本书基于MLOps*实践,提供了在实际场景中设计、训练和部署LLM的原理与实践内容。本书将指导读者构建一个兼具成本效益、可扩展且模块化的LLM Twin系统,突破传统Jupyter Notebook演示的局限,着重讲解如何构建生产级的端到端LLM系统。 本书涵盖数据工程、有监督微调和部署的相关知识,通过手把手地带领读者构建LLM Twin项目,帮助读者将MLOps的原则和组件应用于实际项目。同时,本书还涉及推理优化、偏好对齐和实时数据处理等进阶内容,是那些希望在项目中应用LLM的读者的重要学习资源。 阅读本书,读者将熟练掌握如何部署强大的LLM—既能解决实际问题,又能具备低延迟和高可用的推理能力。无论是AI领域的新手还是经验丰富的从业者,本书提供的深入的理论知识和实用的技巧,*将加深读者对LLM的理解,并提升读者在真实场景中应用它们的能力。
作者简介:
作者简介 保罗·尤斯廷(Paul Iusztin),*机器学习工程师,在生成式 AI、计算机视觉和 MLOps 领域拥有* 7 年的实战经验。曾在 Metaphysic 担任核心工程师,专注于将大型神经网络推向生产环境。 马克西姆·拉博纳(Maxime Labonne)Liquid AI 的后训练负责人,拥有巴黎理工学院机器学习博士学位,并获得谷歌人工智能与机器学习领域(AI / ML)**认证。作为开源社区的活跃贡献者,在 GitHub 上开设了LLM 课程,开发了 LLM Aut 译者简介 孟凡杰,腾讯云技术*,腾讯云原生调度技术负责人,云原生基金会大使,致力于将 AI 技术与云原生技术相结合,探索资源调度的*解决方案。 方佳瑞,清华大学计算机系博士,曾任腾讯云技术*。在机器学习、分布式系统和高性能计算等领域具有丰富的从业经验。
目录:
第 1章 理解LLM Twin的概念与架构 1
1.1 理解LLM Twin的概念 1
1.1.1 什么是LLM Twin 2
1.1.2 为什么构建LLM Twin 3
1.1.3 为什么不使用ChatGPT(或其他类似的聊天机器人) 4
1.2 规划LLM Twin的MVP 5
1.2.1 什么是MVP 5
1.2.2 定义LLM Twin的MVP 5
1.3 基于特征、训练和推理流水线构建机器学习系统 6
1.3.1 构建生产级机器学习系统的挑战 6
1.3.2 以往解决方案的问题 8
1.3.3 解决方案:机器学习系统的流水线 10
1.3.4 FTI流水线的优势 11
1.4 设计LLM Twin的系统架构 12
1.4.1 列出LLM Twin架构的技术细节 12
1.4.2 使用FTI流水线设计LLM Twin架构 13
1.4.3 关于FTI流水线架构和LLM Twin架构的*终思考 17
1.5 小结 18
第 2章 工具与安装 19
2.1 Python生态环境与项目安装 20
2.1.1 Poetry:Python项目依赖与环境管理利器 21
2.1.2 Poe the Poet:Python 项目任务管理* 22
2.2 MLOps与MLOps工具生态 23
2.2.1 Hugging Face:模型仓库 23
2.2.2 ZenML:编排、工件和元数据 24
2.2.3 Comet ML:实验跟踪工具 33
2.2.4 Opik:提示监控 34
2.3 用于存储NoSQL和向量数据的数据库 35
2.3.1 MongoDB:NoSQL数据库 35
2.3.2 Qdrant:向量数据库 35
2.4 为AWS做准备 36
2.4.1 设置AWS账户、访问密钥和CLI 36
2.4.2 SageMaker:训练与推理计算 37
2.5 小结 39
第3章 数据工程 40
3.1 设计LLM Twin的数据采集流水线 41
3.1.1 实现LLM Twin数据采集流水线 44
3.1.2 ZenML流水线及其步骤 44
3.1.3 分发器:实例化正确的爬虫 48
3.1.4 爬虫 50
3.1.5 NoSQL数据仓库文档 59
3.2 采集原始数据并存储到数据仓库 67
3.3 小结 71
第4章 RAG特征流水线 73
4.1 理解RAG 73
4.1.1 为什么使用RAG 74
4.1.2 基础RAG框架 75
4.1.3 什么是嵌入 78
4.1.4 关于向量数据库的更多内容 84
4.2 *RAG技术概览 86
4.2.1 预检索 87
4.2.2 检索 90
4.2.3 后检索 91
4.3 探索LLM Twin的RAG特征流水线架构 93
4.3.1 待解决的问题 93
4.3.2 特征存储 94
4.3.3 原始数据从何而来 94
4.3.4 设计RAG特征流水线架构 94
4.4 实现LLM Twin的RAG特征流水线 101
4.4.1 配置管理 101
4.4.2 ZenML流水线与步骤 102
4.4.3 Pydantic领域实体 109
4.4.4 分发器层 116
4.4.5 处理器 117
4.5 小结 125
第5章 监督微调 127
5.1 构建指令训练数据集 127
5.1.1 构建指令数据集的通用框架 128
5.1.2 数据管理 130
5.1.3 基于规则的过滤 131
5.1.4 数据去重 132
5.1.5 数据净化 133
5.1.6 数据质量评估 133
5.1.7 数据探索 136
5.1.8 数据生成 138
5.1.9 数据增强 139
5.2 构建自定义指令数据集 140
5.3 探索SFT及其关键技术 148
5.3.1 何时进行微调 148
5.3.2 指令数据集格式 149
5.3.3 聊天模板 150
5.3.4 参数*微调技术 151
5.3.5 训练参数 155
5.4 微调技术实践 158
5.5 小结 164
第6章 偏好对齐微调 165
6.1 理解偏好数据集 165
6.1.1 偏好数据 166
6.1.2 数据生成与评估 168
6.2 构建个性化偏好数据集 171
6.3 偏好对齐 177
6.3.1 基于人类反馈的强化学习 178
6.3.2 DPO 179
6.4 实践DPO 181
6.5 小结 187
第7章 LLM的评估方法 188
7.1 模型能力评估 188
7.1.1 机器学习与LLM评估的对比 188
7.1.2 通用LLM评估 189
7.1.3 领域特定LLM评估 191
7.1.4 任务特定LLM评估 193
7.2 RAG系统的评估 195
7.2.1 Ragas 196
7.2.2 ARES 197
7.3 TwinLlama-3.1-8B模型评估 198
7.3.1 生成答案 199
7.3.2 答案评估 200
7.3.3 结果分析 204
7.4 小结 207
第8章 模型推理性能优化 208
8.1 模型优化方法 208
8.1.1 KV cache 209
8.1.2 连续批处理 211
8.1.3 投机解码 212
8.1.4 优化的注意力机制 214
8.2 模型并行化 215
8.2.1 数据并行 215
8.2.2 流水线并行 216
8.2.3 张量并行 217
8.2.4 组合使用并行化方法 218
8.3 模型量化 219
8.3.1 量化简介 219
8.3.2 基于GGUF和llama.cpp的模型量化 223
8.3.3 GPTQ和EXL2量化技术 225
8.3.4 其他量化技术 226
8.4 小结 227
第9章 RAG推理流水线 228
9.1 理解LLM Twin的RAG推理流水线 229
9.2 探索LLM Twin的*RAG技术 230
9.2.1 *RAG预检索优化:查询扩展与自查询 233
9.2.2 *RAG检索优化:过滤向量搜索 239
9.2.3 *RAG后检索优化:重排序 240
9.3 构建基于RAG的LLM Twin推理流水线 243
9.3.1 实现检索模块 243
9.3.2 整合RAG推理流水线 249
9.4 小结 254
第 10章 推理流水线部署 255
10.1 部署方案的选择 256
10.1.1 吞吐量和延迟 256
10.1.2 数据 256
10.1.3 基础设施 257
10.2 深入理解推理部署方案 258
10.2.1 在线实时推理 259
10.2.2 异步推理 260
10.2.3 离线批量转换 260
10.3 模型服务的单体架构与微服务架构 261
10.3.1 单体架构 261
10.3.2 微服务架构 262
10.3.3 单体架构与微服务架构的 选择 264
10.4 探索LLM Twin的推理流水线部署 方案 265
10.5 部署LLM Twin服务 268
10.5.1 基于AWS SageMaker构建LLM 微服务 268
10.5.2 使用FastAPI构建业务 微服务 282
10.6 自动缩放应对突发流量高峰 285
10.6.1 注册缩放目标 287
10.6.2 创建弹性缩放策略 287
10.6.3 缩放限制的上下限设置 288
10.7 小结 289
第 11章 MLOps与LLMOps 290
11.1 LLMOps发展之路:从DevOps和 MLOps寻根 291
11.1.1 DevOps 291
11.1.2 MLOps 293
11.1.3 LLMOps 296
11.2 将LLM Twin流水线部署到云端 299
11.2.1 理解基础架构 300
11.2.2 MongoDB环境配置 301
11.2.3 Qdrant环境配置 302
11.2.4 设置ZenML云环境 303
11.3 为LLM Twin添加LLMOps 313
11.3.1 LLM Twin的CI/CD流水线 工作流程 313
11.3.2 GitHub Actions快速概览 316
11.3.3 CI流水线 316
11.3.4 CD流水线 320
11.3.5 测试CI/CD流水线 322
11.3.6 CT流水线 323
11.3.7 提示监控 327
11.3.8 告警 332
11.4 小结 332
附录 MLOps原则 334
- 人民邮电出版社有限公司 (微信公众号认证)
- 人民邮电出版社微店,为您提供最全面,最专业的一站式购书服务
- 扫描二维码,访问我们的微信店铺
- 随时随地的购物、客服咨询、查询订单和物流...









