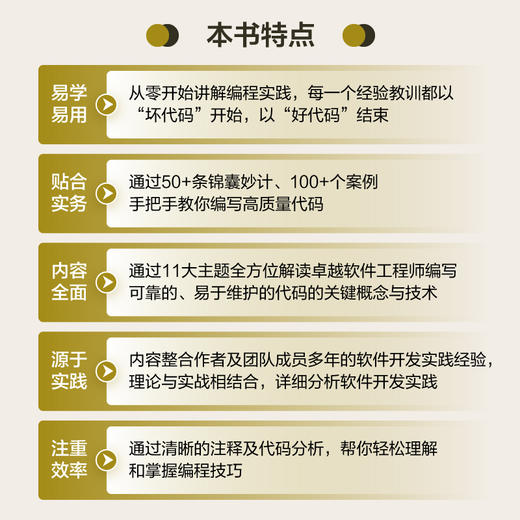
好代码坏代码 软件工程师*之道 高质量代码重构编写编程技能思维 面向对象静态编程入门零基础自学
¥67.40
| 运费: | ¥ 0.00-20.00 |



商品详情
书名:好代码,坏代码:软件工程师*之道
定价:89.8
ISBN:9787115596413
作者:汤姆·朗
版次:第1版
出版时间:2022-11
内容提要:
本书分享的实用技巧可以帮助你编写鲁棒、可靠且易于团队成员理解和适应不断变化需求的代码。内容涉及如何像*的软件工程师一样思考代码,如何编写读起来像一个结构良好的句子的函数,如何确保代码可靠且无错误,如何进行有效的单元测试,如何识别可能导致问题的代码并对其进行改进,如何编写可重用并适应新需求的代码,如何提高读者的中长期生产力,同时还介绍了如何节省开发人员及团队的宝贵时间,等等。
作者简介:
Tom Long,拥有剑桥大学信息工程专业硕士学位,目前担任Google公司*开发工程师,领导一支针对移动设备广告的自动化及优化的技术团队。目前重点关注软件工程、Java开发、团队管理、数据分析、移动广告、技术创新等方向。
目录:
第 一部分 理论
第 1章 代码质量 3
1.1 代码如何变成软件 4
1.2 代码质量目标 6
1.2.1 代码应该正常工作 7
1.2.2 代码应该持续正常工作 7
1.2.3 代码应该适应不断变化的需求 8
1.2.4 代码不应该重复别人做过的工作 9
1.3 代码质量的支柱 10
1.3.1 编写易于理解的代码 10
1.3.2 避免意外 11
1.3.3 编写难以误用的代码 13
1.3.4 编写模块化的代码 14
1.3.5 编写可重用、可推广的代码 15
1.3.6 编写可测试的代码并适当测试 16
1.4 编写高质量代码是否会拖慢进度 17
1.5 小结 19
第 2章 抽象层次 20
2.1 空值和本书中的伪代码惯例 20
2.2 为什么要创建抽象层次 22
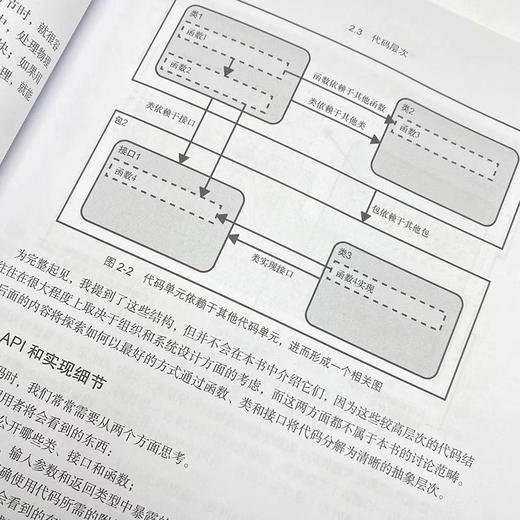
2.3 代码层次 24
2.3.1 API和实现细节 25
2.3.2 函数 26
2.3.3 类 28
2.3.4 接口 36
2.3.5 当层次太薄的时候 39
2.4 微服务简介 40
2.5 小结 41
第3章 其他工程师与代码契约 42
3.1 你的代码和其他工程师的代码 42
3.1.1 对你来说显而易见,但对其他人并不清晰的事情 44
3.1.2 其他工程师无意间试图破坏你的代码 44
3.1.3 过段时间,你会忘记自己的代码的相关情况 44
3.2 其他人如何领会你的代码的使用方法 45
3.2.1 查看代码元素的名称 45
3.2.2 查看代码元素的数据类型 45
3.2.3 阅读文档 46
3.2.4 *自询问 46
3.2.5 查看你的代码 46
3.3 代码契约 47
3.3.1 契约的附属细则 47
3.3.2 不要过分依赖附属细则 49
3.4 检查和断言 53
3.4.1 检查 54
3.4.2 断言 55
3.5 小结 56
第4章 错误 57
4.1 可恢复性 57
4.1.1 可以从中恢复的错误 57
4.1.2 无法从中恢复的错误 58
4.1.3 只有调用者知道能否从某种错误中恢复 58
4.1.4 让调用者意识到他们可能想从中恢复的错误 60
4.2 鲁棒性与故障 60
4.2.1 快速失败 61
4.2.2 大声失败 62
4.2.3 可恢复性的范围 62
4.2.4 不要隐藏错误 64
4.3 错误报告方式 67
4.3.1 回顾:异常 68
4.3.2 显式:受检异常 68
4.3.3 隐式:非受检异常 70
4.3.4 显式:允许为空的返回类型 71
4.3.5 显式:结果返回类型 72
4.3.6 显式:操作结果返回类型 74
4.3.7 隐式:承诺/未来 76
4.3.8 隐式:返回“魔法值” 78
4.4 报告不可恢复的错误 79
4.5 报告调用者可能想要从中恢复的错误 79
4.5.1 使用非受检异常的论据 79
4.5.2 使用显式报错技术的论据 82
4.5.3 我的观点:使用显式报错技术 84
4.6 不要忽视编译器警告 85
4.7 小结 86
*部分 实践
第5章 编写易于理解的代码 91
5.1 使用描述性名称 91
5.1.1 非描述性名称使代码难以理解 91
5.1.2 用注释代替描述性名称是很不好的做法 92
5.1.3 解决方案:使名称具有描述性 93
5.2 适当使用注释 94
5.2.1 多余的注释可能有害 94
5.2.2 注释不是可读代码的合格替代品 95
5.2.3 注释可能很适合于解释代码存在的理由 96
5.2.4 注释可以提供有用的高层概述 96
5.3 不要执着于代码行数 97
5.3.1 避免简短但难以理解的代码 98
5.3.2 解决方案:编写易于理解的代码,即便需要更多行代码 99
5.4 坚持一致的编程风格 99
5.4.1 不一致的编程风格可能引发混乱 100
5.4.2 解决方案:采纳和遵循风格指南 100
5.5 避免深嵌套代码 101
5.5.1 嵌套很深的代码可能难以理解 102
5.5.2 解决方案:改变结构,*限度地减少嵌套 103
5.5.3 嵌套往往是功能过多的结果 103
5.5.4 解决方案:将代码分解为更小的函数 104
5.6 使函数调用易于理解 105
5.6.1 参数可能难以理解 105
5.6.2 解决方案:使用命名参数 105
5.6.3 解决方案:使用描述性类型 106
5.6.4 有时没有很好的解决方案 107
5.6.5 IDE又怎么样呢 108
5.7 避免使用未做解释的值 108
5.7.1 未做解释的值可能令人困惑 109
5.7.2 解决方案:使用恰当命名的常量 110
5.7.3 解决方案:使用恰当命名的函数 110
5.8 正确使用匿名函数 111
5.8.1 匿名函数适合于小的事物 112
5.8.2 匿名函数可能导致代码难以理解 113
5.8.3 解决方案:用命名函数代替 113
5.8.4 大的匿名函数可能造成问题 114
5.8.5 解决方案:将大的匿名函数分解为命名函数 115
5.9 正确使用新奇的编程语言特性 116
5.9.1 新特性可能改善代码 117
5.9.2 不为人知的特性可能引起混乱 117
5.9.3 使用适合于工作的工具 118
5.10 小结 118
第6章 避免意外 119
6.1 避免返回魔法值 119
6.1.1 魔法值可能造成缺陷 120
6.1.2 解决方案:返回空值、可选值或者错误 121
6.1.3 魔法值可能偶然出现 122
6.2 正确使用空对象模式 124
6.2.1 返回空集可能改进代码 125
6.2.2 返回空字符串有时可能造成问题 126
6.2.3 较复杂的空对象可能造成意外 128
6.2.4 空对象实现可能造成意外 129
6.3 避免造成意料之外的副作用 130
6.3.1 明显、有意的副作用没有问题 131
6.3.2 意料之外的副作用可能造成问题 131
6.3.3 解决方案:避免副作用或者使其显而易见 134
6.4 谨防输入参数突变 135
6.4.1 输入参数突变可能导致程序缺陷 136
6.4.2 解决方案:在突变之前复制 137
6.5 避免编写误导性的函数 137
6.5.1 在关键输入缺失时什么*不做可能造成意外 138
6.5.2 解决方案:将关键输入变成*要的输入 140
6.6 永不过时的枚举处理 141
6.6.1 隐式处理未来的枚举值可能造成问题 141
6.6.2 解决方案:使用*的switch语句 143
6.6.3 注意默认情况 144
6.6.4 注意事项:依赖另一个项目的枚举类型 146
6.7 我们不能只用测试解决所有此类问题吗 146
6.8 小结 147
第7章 编写难以被误用的代码 148
7.1 考虑不可变对象 149
7.1.1 可变类可能很容易被误用 149
7.1.2 解决方案:只在构建时设值 151
7.1.3 解决方案:使用不可变性设计模式 152
7.2 考虑实现深度不可变性 157
7.2.1 深度可变性可能导致误用 157
7.2.2 解决方案:防御性复制 159
7.2.3 解决方案:使用不可变数据结构 160
7.3 避免过于通用的类型 161
7.3.1 过于通用的类型可能被误用 162
7.3.2 配对类型很容易被误用 164
7.3.3 解决方案:使用专用类型 166
7.4 处理时间 167
7.4.1 用整数表示时间可能带来问题 168
7.4.2 解决方案:使用合适的数据结构表示时间 170
7.5 拥有单一可信数据源 172
7.5.1 *个可信数据源可能导致无效状态 172
7.5.2 解决方案:使用原始数据作为单一可信数据源 173
7.6 拥有单一可信逻辑来源 175
7.6.1 多个可信逻辑来源可能导致程序缺陷 175
7.6.2 解决方案:使用单一可信来源 177
7.7 小结 179
第8章 实现代码模块化 180
8.1 考虑使用依赖注入 180
8.1.1 硬编程的依赖项可能造成问题 181
8.1.2 解决方案:使用依赖注入 182
8.1.3 在设计代码时考虑依赖注入 184
8.2 倾向于依赖接口 185
8.2.1 依赖于具体实现将限制适应性 186
8.2.2 解决方案:尽可能依赖于接口 186
8.3 注意类的继承 187
8.3.1 类继承可能造成问题 188
8.3.2 解决方案:使用组合 192
8.3.3 真正的“is-a”关系该怎么办 194
8.4 类应该只关心自身 196
8.4.1 过于关心其他类可能造成问题 196
8.4.2 解决方案:使类仅关心自身 197
8.5 将相关联的数据封装在一起 198
8.5.1 未封装的数据可能难以处理 199
8.5.2 解决方案:将相关数据组合为对象或类 200
8.6 防止在返回类型中泄露实现细节 201
8.6.1 在返回类型中泄露实现细节可能造成问题 202
8.6.2 解决方案:返回对应于抽象层次的类型 203
8.7 防止在异常中泄露实现细节 204
8.7.1 在异常中泄露实现细节可能造成问题 204
8.7.2 解决方案:使异常适合抽象层次 206
8.8 小结 208
第9章 编写可重用、可推广的代码 209
9.1 注意各种假设 209
9.1.1 代码重用时假设将导致缺陷 210
9.1.2 解决方案:避免不*要的假设 210
9.1.3 解决方案:如果假设是*要的,则强制实施 211
9.2 注意全局状态 213
9.2.1 全局状态可能使重用变得不* 215
9.2.2 解决方案:依赖注入共享状态 217
9.3 恰当地使用默认返回值 219
9.3.1 低层次代码中的默认返回值可能损害可重用性 220
9.3.2 解决方案:在较高层次代码中使用默认值 221
9.4 保持函数参数的集中度 223
9.4.1 如果函数参数*出需要,可能难以重用 224
9.4.2 解决方案:让函数只取得需要的参数 225
9.5 考虑使用泛型 226
9.5.1 依赖于特定类型将限制可推广性 226
9.5.2 解决方案:使用泛型 227
9.6 小结 228
第三部分 单元测试
第 10章 单元测试原则 231
10.1 单元测试入门 232
10.2 是什么造*好的单元测试 233
10.2.1 *检测破坏 234
10.2.2 与实现细节无关 235
10.2.3 充分解释失败 236
10.2.4 易于理解的测试代码 237
10.2.5 便捷运行 237
10.3 专注于公共API,但不要忽略重要的行为 238
10.4 测试替身 242
10.4.1 使用测试替身的理由 242
10.4.2 模拟对象 246
10.4.3 桩 248
10.4.4 模拟对象和桩可能有问题 250
10.4.5 伪造对象 253
10.4.6 关于模拟对象的不同学派 256
10.5 挑选测试思想 257
10.6 小结 258
第 11章 单元测试实践 259
11.1 测试行为,而不仅仅是函数 259
11.1.1 每个函数一个测试用例往往是不够的 260
11.1.2 解决方案:专注于测试每个行为 261
11.2 避免仅为了测试而使所有细节可见 263
11.2.1 测试私有函数往往是个坏主意 264
11.2.2 解决方案:*通过公共API测试 265
11.2.3 解决方案:将代码分解为较小的单元 266
11.3 一次测试一个行为 270
11.3.1 一次测试多个行为可能导致降低测试质量 270
11.3.2 解决方案:以单独的测试用例测试每个行为 272
11.3.3 参数化测试 273
11.4 恰当地使用共享测试配置 274
11.4.1 共享状态可能带来问题 275
11.4.2 解决方案:避免共享状态或者重置状态 277
11.4.3 共享配置可能带来问题 278
11.4.4 解决方案:在测试用例中定义重要配置 281
11.4.5 何时适用共享配置 283
11.5 使用合适的断言匹配器 284
11.5.1 不合适的匹配器可能导致无法充分解释失败 284
11.5.2 解决方案:使用合适的匹配器 286
11.6 使用依赖注入来提高可测试性 287
11.6.1 硬编程的依赖项可能导致代码无法测试 287
11.6.2 解决方案:使用依赖注入 288
11.7 关于测试的一些结论 289
11.8 小结 290
附录A 巧克力糕饼食谱 291
附录B 空值*与可选类型 292
附录C 额外的代码示例 295
定价:89.8
ISBN:9787115596413
作者:汤姆·朗
版次:第1版
出版时间:2022-11
内容提要:
本书分享的实用技巧可以帮助你编写鲁棒、可靠且易于团队成员理解和适应不断变化需求的代码。内容涉及如何像*的软件工程师一样思考代码,如何编写读起来像一个结构良好的句子的函数,如何确保代码可靠且无错误,如何进行有效的单元测试,如何识别可能导致问题的代码并对其进行改进,如何编写可重用并适应新需求的代码,如何提高读者的中长期生产力,同时还介绍了如何节省开发人员及团队的宝贵时间,等等。
作者简介:
Tom Long,拥有剑桥大学信息工程专业硕士学位,目前担任Google公司*开发工程师,领导一支针对移动设备广告的自动化及优化的技术团队。目前重点关注软件工程、Java开发、团队管理、数据分析、移动广告、技术创新等方向。
目录:
第 一部分 理论
第 1章 代码质量 3
1.1 代码如何变成软件 4
1.2 代码质量目标 6
1.2.1 代码应该正常工作 7
1.2.2 代码应该持续正常工作 7
1.2.3 代码应该适应不断变化的需求 8
1.2.4 代码不应该重复别人做过的工作 9
1.3 代码质量的支柱 10
1.3.1 编写易于理解的代码 10
1.3.2 避免意外 11
1.3.3 编写难以误用的代码 13
1.3.4 编写模块化的代码 14
1.3.5 编写可重用、可推广的代码 15
1.3.6 编写可测试的代码并适当测试 16
1.4 编写高质量代码是否会拖慢进度 17
1.5 小结 19
第 2章 抽象层次 20
2.1 空值和本书中的伪代码惯例 20
2.2 为什么要创建抽象层次 22
2.3 代码层次 24
2.3.1 API和实现细节 25
2.3.2 函数 26
2.3.3 类 28
2.3.4 接口 36
2.3.5 当层次太薄的时候 39
2.4 微服务简介 40
2.5 小结 41
第3章 其他工程师与代码契约 42
3.1 你的代码和其他工程师的代码 42
3.1.1 对你来说显而易见,但对其他人并不清晰的事情 44
3.1.2 其他工程师无意间试图破坏你的代码 44
3.1.3 过段时间,你会忘记自己的代码的相关情况 44
3.2 其他人如何领会你的代码的使用方法 45
3.2.1 查看代码元素的名称 45
3.2.2 查看代码元素的数据类型 45
3.2.3 阅读文档 46
3.2.4 *自询问 46
3.2.5 查看你的代码 46
3.3 代码契约 47
3.3.1 契约的附属细则 47
3.3.2 不要过分依赖附属细则 49
3.4 检查和断言 53
3.4.1 检查 54
3.4.2 断言 55
3.5 小结 56
第4章 错误 57
4.1 可恢复性 57
4.1.1 可以从中恢复的错误 57
4.1.2 无法从中恢复的错误 58
4.1.3 只有调用者知道能否从某种错误中恢复 58
4.1.4 让调用者意识到他们可能想从中恢复的错误 60
4.2 鲁棒性与故障 60
4.2.1 快速失败 61
4.2.2 大声失败 62
4.2.3 可恢复性的范围 62
4.2.4 不要隐藏错误 64
4.3 错误报告方式 67
4.3.1 回顾:异常 68
4.3.2 显式:受检异常 68
4.3.3 隐式:非受检异常 70
4.3.4 显式:允许为空的返回类型 71
4.3.5 显式:结果返回类型 72
4.3.6 显式:操作结果返回类型 74
4.3.7 隐式:承诺/未来 76
4.3.8 隐式:返回“魔法值” 78
4.4 报告不可恢复的错误 79
4.5 报告调用者可能想要从中恢复的错误 79
4.5.1 使用非受检异常的论据 79
4.5.2 使用显式报错技术的论据 82
4.5.3 我的观点:使用显式报错技术 84
4.6 不要忽视编译器警告 85
4.7 小结 86
*部分 实践
第5章 编写易于理解的代码 91
5.1 使用描述性名称 91
5.1.1 非描述性名称使代码难以理解 91
5.1.2 用注释代替描述性名称是很不好的做法 92
5.1.3 解决方案:使名称具有描述性 93
5.2 适当使用注释 94
5.2.1 多余的注释可能有害 94
5.2.2 注释不是可读代码的合格替代品 95
5.2.3 注释可能很适合于解释代码存在的理由 96
5.2.4 注释可以提供有用的高层概述 96
5.3 不要执着于代码行数 97
5.3.1 避免简短但难以理解的代码 98
5.3.2 解决方案:编写易于理解的代码,即便需要更多行代码 99
5.4 坚持一致的编程风格 99
5.4.1 不一致的编程风格可能引发混乱 100
5.4.2 解决方案:采纳和遵循风格指南 100
5.5 避免深嵌套代码 101
5.5.1 嵌套很深的代码可能难以理解 102
5.5.2 解决方案:改变结构,*限度地减少嵌套 103
5.5.3 嵌套往往是功能过多的结果 103
5.5.4 解决方案:将代码分解为更小的函数 104
5.6 使函数调用易于理解 105
5.6.1 参数可能难以理解 105
5.6.2 解决方案:使用命名参数 105
5.6.3 解决方案:使用描述性类型 106
5.6.4 有时没有很好的解决方案 107
5.6.5 IDE又怎么样呢 108
5.7 避免使用未做解释的值 108
5.7.1 未做解释的值可能令人困惑 109
5.7.2 解决方案:使用恰当命名的常量 110
5.7.3 解决方案:使用恰当命名的函数 110
5.8 正确使用匿名函数 111
5.8.1 匿名函数适合于小的事物 112
5.8.2 匿名函数可能导致代码难以理解 113
5.8.3 解决方案:用命名函数代替 113
5.8.4 大的匿名函数可能造成问题 114
5.8.5 解决方案:将大的匿名函数分解为命名函数 115
5.9 正确使用新奇的编程语言特性 116
5.9.1 新特性可能改善代码 117
5.9.2 不为人知的特性可能引起混乱 117
5.9.3 使用适合于工作的工具 118
5.10 小结 118
第6章 避免意外 119
6.1 避免返回魔法值 119
6.1.1 魔法值可能造成缺陷 120
6.1.2 解决方案:返回空值、可选值或者错误 121
6.1.3 魔法值可能偶然出现 122
6.2 正确使用空对象模式 124
6.2.1 返回空集可能改进代码 125
6.2.2 返回空字符串有时可能造成问题 126
6.2.3 较复杂的空对象可能造成意外 128
6.2.4 空对象实现可能造成意外 129
6.3 避免造成意料之外的副作用 130
6.3.1 明显、有意的副作用没有问题 131
6.3.2 意料之外的副作用可能造成问题 131
6.3.3 解决方案:避免副作用或者使其显而易见 134
6.4 谨防输入参数突变 135
6.4.1 输入参数突变可能导致程序缺陷 136
6.4.2 解决方案:在突变之前复制 137
6.5 避免编写误导性的函数 137
6.5.1 在关键输入缺失时什么*不做可能造成意外 138
6.5.2 解决方案:将关键输入变成*要的输入 140
6.6 永不过时的枚举处理 141
6.6.1 隐式处理未来的枚举值可能造成问题 141
6.6.2 解决方案:使用*的switch语句 143
6.6.3 注意默认情况 144
6.6.4 注意事项:依赖另一个项目的枚举类型 146
6.7 我们不能只用测试解决所有此类问题吗 146
6.8 小结 147
第7章 编写难以被误用的代码 148
7.1 考虑不可变对象 149
7.1.1 可变类可能很容易被误用 149
7.1.2 解决方案:只在构建时设值 151
7.1.3 解决方案:使用不可变性设计模式 152
7.2 考虑实现深度不可变性 157
7.2.1 深度可变性可能导致误用 157
7.2.2 解决方案:防御性复制 159
7.2.3 解决方案:使用不可变数据结构 160
7.3 避免过于通用的类型 161
7.3.1 过于通用的类型可能被误用 162
7.3.2 配对类型很容易被误用 164
7.3.3 解决方案:使用专用类型 166
7.4 处理时间 167
7.4.1 用整数表示时间可能带来问题 168
7.4.2 解决方案:使用合适的数据结构表示时间 170
7.5 拥有单一可信数据源 172
7.5.1 *个可信数据源可能导致无效状态 172
7.5.2 解决方案:使用原始数据作为单一可信数据源 173
7.6 拥有单一可信逻辑来源 175
7.6.1 多个可信逻辑来源可能导致程序缺陷 175
7.6.2 解决方案:使用单一可信来源 177
7.7 小结 179
第8章 实现代码模块化 180
8.1 考虑使用依赖注入 180
8.1.1 硬编程的依赖项可能造成问题 181
8.1.2 解决方案:使用依赖注入 182
8.1.3 在设计代码时考虑依赖注入 184
8.2 倾向于依赖接口 185
8.2.1 依赖于具体实现将限制适应性 186
8.2.2 解决方案:尽可能依赖于接口 186
8.3 注意类的继承 187
8.3.1 类继承可能造成问题 188
8.3.2 解决方案:使用组合 192
8.3.3 真正的“is-a”关系该怎么办 194
8.4 类应该只关心自身 196
8.4.1 过于关心其他类可能造成问题 196
8.4.2 解决方案:使类仅关心自身 197
8.5 将相关联的数据封装在一起 198
8.5.1 未封装的数据可能难以处理 199
8.5.2 解决方案:将相关数据组合为对象或类 200
8.6 防止在返回类型中泄露实现细节 201
8.6.1 在返回类型中泄露实现细节可能造成问题 202
8.6.2 解决方案:返回对应于抽象层次的类型 203
8.7 防止在异常中泄露实现细节 204
8.7.1 在异常中泄露实现细节可能造成问题 204
8.7.2 解决方案:使异常适合抽象层次 206
8.8 小结 208
第9章 编写可重用、可推广的代码 209
9.1 注意各种假设 209
9.1.1 代码重用时假设将导致缺陷 210
9.1.2 解决方案:避免不*要的假设 210
9.1.3 解决方案:如果假设是*要的,则强制实施 211
9.2 注意全局状态 213
9.2.1 全局状态可能使重用变得不* 215
9.2.2 解决方案:依赖注入共享状态 217
9.3 恰当地使用默认返回值 219
9.3.1 低层次代码中的默认返回值可能损害可重用性 220
9.3.2 解决方案:在较高层次代码中使用默认值 221
9.4 保持函数参数的集中度 223
9.4.1 如果函数参数*出需要,可能难以重用 224
9.4.2 解决方案:让函数只取得需要的参数 225
9.5 考虑使用泛型 226
9.5.1 依赖于特定类型将限制可推广性 226
9.5.2 解决方案:使用泛型 227
9.6 小结 228
第三部分 单元测试
第 10章 单元测试原则 231
10.1 单元测试入门 232
10.2 是什么造*好的单元测试 233
10.2.1 *检测破坏 234
10.2.2 与实现细节无关 235
10.2.3 充分解释失败 236
10.2.4 易于理解的测试代码 237
10.2.5 便捷运行 237
10.3 专注于公共API,但不要忽略重要的行为 238
10.4 测试替身 242
10.4.1 使用测试替身的理由 242
10.4.2 模拟对象 246
10.4.3 桩 248
10.4.4 模拟对象和桩可能有问题 250
10.4.5 伪造对象 253
10.4.6 关于模拟对象的不同学派 256
10.5 挑选测试思想 257
10.6 小结 258
第 11章 单元测试实践 259
11.1 测试行为,而不仅仅是函数 259
11.1.1 每个函数一个测试用例往往是不够的 260
11.1.2 解决方案:专注于测试每个行为 261
11.2 避免仅为了测试而使所有细节可见 263
11.2.1 测试私有函数往往是个坏主意 264
11.2.2 解决方案:*通过公共API测试 265
11.2.3 解决方案:将代码分解为较小的单元 266
11.3 一次测试一个行为 270
11.3.1 一次测试多个行为可能导致降低测试质量 270
11.3.2 解决方案:以单独的测试用例测试每个行为 272
11.3.3 参数化测试 273
11.4 恰当地使用共享测试配置 274
11.4.1 共享状态可能带来问题 275
11.4.2 解决方案:避免共享状态或者重置状态 277
11.4.3 共享配置可能带来问题 278
11.4.4 解决方案:在测试用例中定义重要配置 281
11.4.5 何时适用共享配置 283
11.5 使用合适的断言匹配器 284
11.5.1 不合适的匹配器可能导致无法充分解释失败 284
11.5.2 解决方案:使用合适的匹配器 286
11.6 使用依赖注入来提高可测试性 287
11.6.1 硬编程的依赖项可能导致代码无法测试 287
11.6.2 解决方案:使用依赖注入 288
11.7 关于测试的一些结论 289
11.8 小结 290
附录A 巧克力糕饼食谱 291
附录B 空值*与可选类型 292
附录C 额外的代码示例 295
- 人民邮电出版社有限公司 (微信公众号认证)
- 人民邮电出版社微店,为您提供最全面,最专业的一站式购书服务
- 扫描二维码,访问我们的微信店铺
- 随时随地的购物、客服咨询、查询订单和物流...









