从*构建大模型 大模型应用开发入门 LLM提示工程师 图解GPT deepseek大模型机器学习深度学习人工智能书籍
¥82.40
| 运费: | ¥ 0.00-20.00 |



商品详情
书名:从*构建大模型
定价:109.8
ISBN:9787115666000
作者:[美]塞巴斯蒂安·拉施卡(Sebastian Raschka)
版次:第1版
出版时间:2025-04
内容提要:
本书是关于如何从*开始构建大模型的指南,由*书作家塞巴斯蒂安·拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。
作者简介:
塞巴斯蒂安·拉施卡(Sebastian Raschka),*影响力的人工智能*,本书配套GitHub项目LLMs-from-scratch达4万星。现在大模型独角兽公司Lightning Al任*研究工程师。博士毕业于密歇根州立大学,2018~2023年威斯康星大学麦迪逊分校助理教授(终身教职),从事深度学习科研和教学。除本书外,他还写作了*书《大模型技术30讲》和《Python机器学习》。 【译者简介】 覃立波,中南大学特聘教授,博士生导师。现任中国中文信息学会青工委秘书长。主要研究兴趣为人工智能、自然语言处理、大模型等。曾担任ACL.EMNLP、NAACL、IJCAI等国际会议领域主席或*程序委员会委员。 冯骁骋,哈尔滨工业大学计算学部社会计算与交互机器人研究中心教授,博士生导师,人工智能学院副院长。研究兴趣包括自然语言处理、大模型等。在ACL、AAAl、IJCAl、TKDE、TOIS 等CCFA/B类国际会议及期刊发表论文50余篇。 刘乾,新加坡某公司的研究科学家,主要研究方向是代码生成与自然语言推理。他在*人工智能会议(如ICLR、NeurlPS、ICML)上发表了数十篇论文,曾获得2020年百度奖学金提名奖、北京市2023年*博士论文提名奖、2024年 KAUST Rising Stars in Al等荣誉。 【主审人简介】 车万翔,哈尔滨工业大学计算学部长聘教授,博士生导师,人工智能研究院副院长,*青年人才,斯坦福大学访问学者。 黄科科,中南大学教授,博士生导师,自动化学院副院长,*青年人才。
目录:
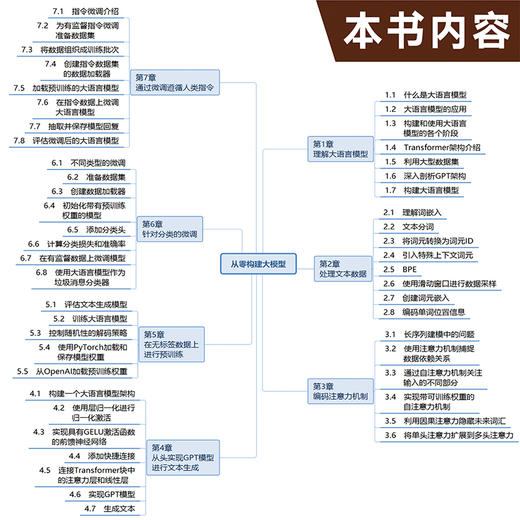
第 1章 理解大语言模型 1
1.1 什么是大语言模型 2
1.2 大语言模型的应用 3
1.3 构建和使用大语言模型的各个阶段 4
1.4 Transformer架构介绍 6
1.5 利用大型数据集 9
1.6 深入剖析GPT架构 11
1.7 构建大语言模型 13
1.8 小结 14
第 2章 处理文本数据 15
2.1 理解词嵌入 16
2.2 文本分词 18
2.3 将词元转换为词元ID 21
2.4 引入特殊上下文词元 25
2.5 BPE 29
2.6 使用滑动窗口进行数据采样 31
2.7 创建词元嵌入 37
2.8 编码单词位置信息 40
2.9 小结 44
第3章 编码注意力机制 45
3.1 长序列建模中的问题 46
3.2 使用注意力机制捕捉数据依赖关系 48
3.3 通过自注意力机制关注输入的不同部分 49
3.3.1 无可训练权重的简单自注意力机制 50
3.3.2 计算所有输入词元的注意力权重 54
3.4 实现带可训练权重的自注意力机制 57
3.4.1 逐步计算注意力权重 58
3.4.2 实现一个简化的自注意力Python类 63
3.5 利用因果注意力隐藏未来词汇 66
3.5.1 因果注意力的掩码实现 67
3.5.2 利用dropout掩码额外的注意力权重 70
3.5.3 实现一个简化的因果注意力类 72
3.6 将单头注意力扩展到多头注意力 74
3.6.1 叠加多个单头注意力层 74
3.6.2 通过权重划分实现多头注意力 77
3.7 小结 82
第4章 从头实现GPT模型进行文本生成 83
4.1 构建一个大语言模型架构 84
4.2 使用层归一化进行归一化* 89
4.3 实现具有GELU*函数的前馈神经网络 94
4.4 添加快捷连接 99
4.5 连接Transformer块中的注意力层和线性层 102
4.6 实现GPT模型 105
4.7 生成文本 110
4.8 小结 115
第5章 在无标签数据上进行预训练 116
5.1 评估文本生成模型 117
5.1.1 使用GPT来生成文本 117
5.1.2 计算文本生成损失 119
5.1.3 计算训练集和验证集的损失 126
5.2 训练大语言模型 131
5.3 控制随机性的解码策略 137
5.3.1 温度缩放 138
5.3.2 Top-k采样 141
5.3.3 修改文本生成函数 142
5.4 使用PyTorch加载和保存模型权重 144
5.5 从OpenAI加载预训练权重 145
5.6 小结 152
第6章 针对分类的微调 153
6.1 不同类型的微调 154
6.2 准备数据集 155
6.3 创建数据加载器 159
6.4 初始化带有预训练权重的模型 163
6.5 添加分类头 166
6.6 计算分类损失和*率 172
6.7 在有监督数据上微调模型 176
6.8 使用大语言模型作为垃圾消息分类器 182
6.9 小结 184
第7章 通过微调遵循人类指令 185
7.1 指令微调介绍 186
7.2 为有监督指令微调准备数据集 187
7.3 将数据组织成训练批次 190
7.4 创建指令数据集的数据加载器 201
7.5 加载预训练的大语言模型 204
7.6 在指令数据上微调大语言模型 207
7.7 抽取并保存模型回复 211
7.8 评估微调后的大语言模型 216
7.9 结论 224
7.9.1 下一步 225
7.9.2 跟上领域的*进展 225
7.9.3 写在* 225
7.10 小结 225
附录A PyTorch简介 227
附录B 参考文献和延伸阅读 263
附录C 练习的解决方案 273
附录D 为训练循环添加更多细节和优化功能 285
附录E 使用LoRA进行参数*微调 294
附录F 理解推理大语言模型:构建与优化推理模型的方法和策略 308
定价:109.8
ISBN:9787115666000
作者:[美]塞巴斯蒂安·拉施卡(Sebastian Raschka)
版次:第1版
出版时间:2025-04
内容提要:
本书是关于如何从*开始构建大模型的指南,由*书作家塞巴斯蒂安·拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。
作者简介:
塞巴斯蒂安·拉施卡(Sebastian Raschka),*影响力的人工智能*,本书配套GitHub项目LLMs-from-scratch达4万星。现在大模型独角兽公司Lightning Al任*研究工程师。博士毕业于密歇根州立大学,2018~2023年威斯康星大学麦迪逊分校助理教授(终身教职),从事深度学习科研和教学。除本书外,他还写作了*书《大模型技术30讲》和《Python机器学习》。 【译者简介】 覃立波,中南大学特聘教授,博士生导师。现任中国中文信息学会青工委秘书长。主要研究兴趣为人工智能、自然语言处理、大模型等。曾担任ACL.EMNLP、NAACL、IJCAI等国际会议领域主席或*程序委员会委员。 冯骁骋,哈尔滨工业大学计算学部社会计算与交互机器人研究中心教授,博士生导师,人工智能学院副院长。研究兴趣包括自然语言处理、大模型等。在ACL、AAAl、IJCAl、TKDE、TOIS 等CCFA/B类国际会议及期刊发表论文50余篇。 刘乾,新加坡某公司的研究科学家,主要研究方向是代码生成与自然语言推理。他在*人工智能会议(如ICLR、NeurlPS、ICML)上发表了数十篇论文,曾获得2020年百度奖学金提名奖、北京市2023年*博士论文提名奖、2024年 KAUST Rising Stars in Al等荣誉。 【主审人简介】 车万翔,哈尔滨工业大学计算学部长聘教授,博士生导师,人工智能研究院副院长,*青年人才,斯坦福大学访问学者。 黄科科,中南大学教授,博士生导师,自动化学院副院长,*青年人才。
目录:
第 1章 理解大语言模型 1
1.1 什么是大语言模型 2
1.2 大语言模型的应用 3
1.3 构建和使用大语言模型的各个阶段 4
1.4 Transformer架构介绍 6
1.5 利用大型数据集 9
1.6 深入剖析GPT架构 11
1.7 构建大语言模型 13
1.8 小结 14
第 2章 处理文本数据 15
2.1 理解词嵌入 16
2.2 文本分词 18
2.3 将词元转换为词元ID 21
2.4 引入特殊上下文词元 25
2.5 BPE 29
2.6 使用滑动窗口进行数据采样 31
2.7 创建词元嵌入 37
2.8 编码单词位置信息 40
2.9 小结 44
第3章 编码注意力机制 45
3.1 长序列建模中的问题 46
3.2 使用注意力机制捕捉数据依赖关系 48
3.3 通过自注意力机制关注输入的不同部分 49
3.3.1 无可训练权重的简单自注意力机制 50
3.3.2 计算所有输入词元的注意力权重 54
3.4 实现带可训练权重的自注意力机制 57
3.4.1 逐步计算注意力权重 58
3.4.2 实现一个简化的自注意力Python类 63
3.5 利用因果注意力隐藏未来词汇 66
3.5.1 因果注意力的掩码实现 67
3.5.2 利用dropout掩码额外的注意力权重 70
3.5.3 实现一个简化的因果注意力类 72
3.6 将单头注意力扩展到多头注意力 74
3.6.1 叠加多个单头注意力层 74
3.6.2 通过权重划分实现多头注意力 77
3.7 小结 82
第4章 从头实现GPT模型进行文本生成 83
4.1 构建一个大语言模型架构 84
4.2 使用层归一化进行归一化* 89
4.3 实现具有GELU*函数的前馈神经网络 94
4.4 添加快捷连接 99
4.5 连接Transformer块中的注意力层和线性层 102
4.6 实现GPT模型 105
4.7 生成文本 110
4.8 小结 115
第5章 在无标签数据上进行预训练 116
5.1 评估文本生成模型 117
5.1.1 使用GPT来生成文本 117
5.1.2 计算文本生成损失 119
5.1.3 计算训练集和验证集的损失 126
5.2 训练大语言模型 131
5.3 控制随机性的解码策略 137
5.3.1 温度缩放 138
5.3.2 Top-k采样 141
5.3.3 修改文本生成函数 142
5.4 使用PyTorch加载和保存模型权重 144
5.5 从OpenAI加载预训练权重 145
5.6 小结 152
第6章 针对分类的微调 153
6.1 不同类型的微调 154
6.2 准备数据集 155
6.3 创建数据加载器 159
6.4 初始化带有预训练权重的模型 163
6.5 添加分类头 166
6.6 计算分类损失和*率 172
6.7 在有监督数据上微调模型 176
6.8 使用大语言模型作为垃圾消息分类器 182
6.9 小结 184
第7章 通过微调遵循人类指令 185
7.1 指令微调介绍 186
7.2 为有监督指令微调准备数据集 187
7.3 将数据组织成训练批次 190
7.4 创建指令数据集的数据加载器 201
7.5 加载预训练的大语言模型 204
7.6 在指令数据上微调大语言模型 207
7.7 抽取并保存模型回复 211
7.8 评估微调后的大语言模型 216
7.9 结论 224
7.9.1 下一步 225
7.9.2 跟上领域的*进展 225
7.9.3 写在* 225
7.10 小结 225
附录A PyTorch简介 227
附录B 参考文献和延伸阅读 263
附录C 练习的解决方案 273
附录D 为训练循环添加更多细节和优化功能 285
附录E 使用LoRA进行参数*微调 294
附录F 理解推理大语言模型:构建与优化推理模型的方法和策略 308
- 人民邮电出版社有限公司 (微信公众号认证)
- 人民邮电出版社微店,为您提供最全面,最专业的一站式购书服务
- 扫描二维码,访问我们的微信店铺
- 随时随地的购物、客服咨询、查询订单和物流...









