


商品详情
书名:深度强化学习
定价:129.8
ISBN:9787115600691
作者:王树森,黎彧君,张志华
版次:第1版
出版时间:2022-11
内容提要:
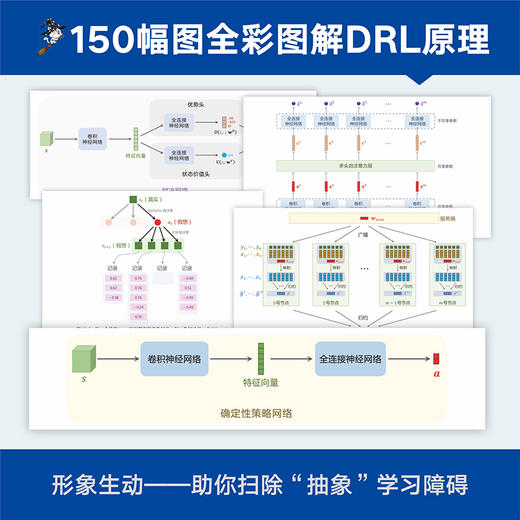
本书基于备受读者推崇的王树森“深度强化学习”系列公开视频课,专门解决“入门深度强化学习难”的问题。 本书的独特之处在于:*,知识精简,剔除一切不*要的概念和公式,学起来轻松;*,内容新颖,聚焦近10年深度强化学习领域的突破,让你一上手*紧跟*。本书系统讲解深度强化学习的原理与实现,但不回避数学公式和各种模型,原创100多幅精美插图,并以全彩印刷展示。简洁清晰的语言+生动形象的图示,助你扫除任何可能的学习障碍!本书内容分为五部分:基础知识、价值学习、策略学习、多智能体强化学习、应用与展望,涉及DQN、A3C、TRPO、DDPG、AlphaGo等。 本书面向深度强化学习入门读者,助你构建完整的知识体系。学完本书,你能够轻松看懂深度强化学习的实现代码、读懂该领域的论文、听懂学术报告,具备进一步自学和深挖的能力。
作者简介:
王树森 现任小红书基础模型团队负责人,从事搜索和推荐算法研发工作。从浙江大学获得计算机学士和博士学位,*读期间获得“微软学者”和“百度奖学金”等多项荣誉。在加入小红书之前,曾任美国加州大学伯克利分校博士后、美国史蒂文斯理工学院助理教授、博导。在机器学习、强化学习、数值计算、分布式计算等方向有多年科研经验,在计算机国际*期刊和会议上发表30多篇论文。 在YouTube、B站开设“深度强化学习”“深度学习”“推荐系统”公开课(ID:Shusen Wang),全网视频播放量100万次。 黎彧君 华为诺亚方舟实验室*研究员,主要从事AutoML相关的研发工作。上海交通大学博士,研究方向为数值优化、强化学习;攻读博士学位期间曾前往普林斯顿大学访问一年。共同翻译出版“花书”《深度学习》。 张志华 北京大学数学科学学院教授。此前先后执教于浙江大学和上海交通大学,任计算机科学教授。主要从事统计学、机器学习与计算机科学领域的研究和教学。曾主讲“统计机器学习”“机器学习导论”“深度学习”“强化学习”,其课程视频广受欢迎。
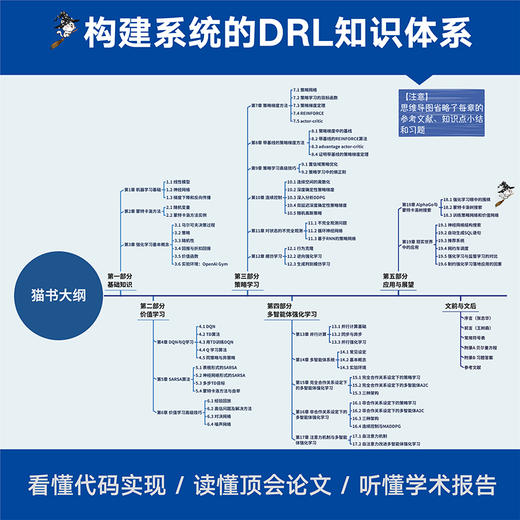
目录:
序言 i
前言 v
常用符号 xi
第 一部分 基础知识
第 1章 机器学习基础 2
1.1 线性模型 2
1.1.1 线性回归 2
1.1.2 逻辑斯谛回归 4
1.1.3 softmax分类器 7
1.2 神经网络 10
1.2.1 全连接神经网络 10
1.2.2 卷积神经网络 11
1.3 梯度下降和反向传播 12
1.3.1 梯度下降 13
1.3.2 反向传播 14
知识点小结 16
习题 16
第 2章 蒙特卡洛方法 18
2.1 随机变量 18
2.2 蒙特卡洛方法实例 21
2.2.1 例一:近似π值 21
2.2.2 例二:估算阴影部分面积 23
2.2.3 例三:近似定积分 25
2.2.4 例四:近似期望 26
2.2.5 例五:随机梯度 27
知识点小结 29
习题 29
第3章 强化学习基本概念 31
3.1 马尔可夫决策过程 31
3.1.1 状态、动作、奖励 31
3.1.2 状态转移 32
3.2 策略 33
3.3 随机性 35
3.4 回报与折扣回报 37
3.4.1 回报 37
3.4.2 折扣回报 37
3.4.3 回报中的随机性 38
3.4.4 有限期MDP和无限期MDP 39
3.5 价值函数 39
3.5.1 动作价值函数 40
3.5.2 *动作价值函数 40
3.5.3 状态价值函数 41
3.6 实验环境:OpenAI Gym 42
知识点小结 44
习题 44
*部分 价值学习
第4章 DQN与Q学习 48
4.1 DQN 48
4.1.1 概念回顾 48
4.1.2 DQN表达式 49
4.1.3 DQN的梯度 50
4.2 TD算法 50
4.2.1 驾车时间预测示例 50
4.2.2 TD算法的原理 51
4.3 用TD训练DQN 53
4.3.1 算法推导 53
4.3.2 训练流程 55
4.4 Q 学习算法 57
4.4.1 表格形式的Q学习 57
4.4.2 算法推导 57
4.4.3 训练流程 58
4.5 同策略与异策略 59
相关文献 60
知识点小结 61
习题 61
第5章 SARSA算法 63
5.1 表格形式的SARSA 63
5.1.1 算法推导 63
5.1.2 训练流程 64
5.1.3 Q学习与SARSA的对比 65
5.2 神经网络形式的SARSA 66
5.2.1 价值网络 66
5.2.2 算法推导 66
5.2.3 训练流程 67
5.3 多步TD目标 68
5.3.1 算法推导 68
5.3.2 多步TD目标的原理 69
5.3.3 训练流程 70
5.4 蒙特卡洛方法与自举 70
5.4.1 蒙特卡洛方法 71
5.4.2 自举 71
5.4.3 蒙特卡洛方法和自举的对比 72
相关文献 73
知识点小结 73
习题 74
第6章 价值学习*技巧 75
6.1 经验回放 75
6.1.1 经验回放的优点 76
6.1.2 经验回放的局限性 76
6.1.3 优先经验回放 77
6.2 高估问题及解决方法 79
6.2.1 自举导致偏差传播 79
6.2.2 *化导致高估 80
6.2.3 高估的危害 81
6.2.4 使用目标网络 82
6.2.5 双Q学习算法 84
6.2.6 总结 85
6.3 对决网络 86
6.3.1 *优势函数 86
6.3.2 对决网络的结构 87
6.3.3 解决不*性 88
6.3.4 对决网络的实际实现 89
6.4 噪声网络 90
6.4.1 噪声网络的原理 90
6.4.2 噪声DQN 91
6.4.3 训练流程 93
相关文献 94
知识点小结 94
习题 94
第三部分 策略学习
第7章 策略梯度方法 98
7.1 策略网络 98
7.2 策略学习的目标函数 99
7.3 策略梯度定理 101
7.3.1 简化证明 101
7.3.2 严格证明 102
7.3.3 近似策略梯度 106
7.4 REINFORCE 107
7.4.1 简化推导 108
7.4.2 训练流程 108
7.4.3 严格推导 109
7.5 actor-critic 110
7.5.1 价值网络 110
7.5.2 算法推导 111
7.5.3 训练流程 114
7.5.4 用目标网络改进训练 114
相关文献 115
知识点小结 115
习题 116
第8章 带基线的策略梯度方法 117
8.1 策略梯度中的基线 117
8.1.1 基线的引入 117
8.1.2 基线的直观解释 118
8.2 带基线的REINFORCE算法 119
8.2.1 策略网络和价值网络 120
8.2.2 算法推导 121
8.2.3 训练流程 121
8.3 advantage actor-critic 122
8.3.1 算法推导 123
8.3.2 训练流程 125
8.3.3 用目标网络改进训练 126
8.4 证明带基线的策略梯度定理 127
知识点小结 128
习题 128
第9章 策略学习*技巧 129
9.1 置信域策略优化 129
9.1.1 置信域方法 129
9.1.2 策略学习的目标函数 132
9.1.3 算法推导 133
9.1.4 训练流程 135
9.2 策略学习中的熵正则 135
相关文献 138
知识点小结 138
第 10章 连续控制 139
10.1 连续空间的离散化 139
10.2 深度确定性策略梯度 140
10.2.1 策略网络和价值网络 140
10.2.2 算法推导 142
10.3 深入分析DDPG 145
10.3.1 从策略学习的角度看待DDPG 145
10.3.2 从价值学习的角度看待DDPG 146
10.3.3 DDPG的高估问题 147
10.4 双延迟深度确定性策略梯度 148
10.4.1 高估问题的解决方案——目标网络 148
10.4.2 高估问题的解决方案——截断双Q学习 148
10.4.3 其他改进点 149
10.4.4 训练流程 150
10.5 随机高斯策略 151
10.5.1 基本思路 152
10.5.2 随机高斯策略网络 153
10.5.3 策略梯度 154
10.5.4 用REINFORCE学习参数 155
10.5.5 用actor-critic学习参数 155
相关文献 157
知识点小结 157
第 11章 对状态的不完全观测 158
11.1 不完全观测问题 158
11.2 循环神经网络 159
11.3 基于RNN的策略网络 161
相关文献 162
知识点小结 163
习题 163
第 12章 模仿学习 165
12.1 行为克隆 165
12.1.1 连续控制问题 165
12.1.2 离散控制问题 166
12.1.3 行为克隆与强化学习的对比 168
12.2 逆向强化学习 169
12.2.1 IRL的基本设定 169
12.2.2 IRL的基本思想 170
12.2.3 从黑箱策略反推奖励 170
12.2.4 用奖励函数训练策略网络 171
12.3 生成判别模仿学习 171
12.3.1 生成判别网络 172
12.3.2 GAIL的生成器和判别器 175
12.3.3 GAIL的训练 176
相关文献 178
知识点小结 179
第四部分 多智能体强化学习
第 13章 并行计算 182
13.1 并行计算基础 182
13.1.1 并行梯度下降 182
13.1.2 MapReduce 183
13.1.3 用 MapReduce实现并行梯度下降 184
13.1.4 并行计算的代价 187
13.2 同步与异步 188
13.2.1 同步算法 188
13.2.2 异步算法 189
13.2.3 同步梯度下降与异步梯度下降的对比 191
13.3 并行强化学习 191
13.3.1 异步并行双Q学习 191
13.3.2 A3C:异步并行A2C 193
相关文献 195
知识点小结 195
习题 196
第 14章 多智能体系统 197
14.1 常见设定 197
14.2 基本概念 199
14.2.1 专业术语 199
14.2.2 策略网络 200
14.2.3 动作价值函数 200
14.2.4 状态价值函数 201
14.3 实验环境 202
14.3.1 multi-agent particle world 202
14.3.2 StarCraft multi-agent challenge 204
14.3.3 Hanabi Challenge 205
相关文献 206
知识点小结 206
第 15章 完全合作关系设定下的多智能体强化学习 207
15.1 完全合作关系设定下的策略学习 208
15.2 完全合作关系设定下的多智能体A2C 209
15.2.1 策略网络和价值网络 209
15.2.2 训练和决策 211
15.2.3 实现中的难点 212
15.3 三种架构 213
15.3.1 中心化训练+中心化决策 214
15.3.2 去中心化训练+去中心化决策 215
15.3.3 中心化训练+去中心化决策 217
相关文献 219
知识点小结 220
习题 220
第 16章 非合作关系设定下的多智能体强化学习 221
16.1 非合作关系设定下的策略学习 222
16.1.1 非合作关系设定下的目标函数 222
16.1.2 收敛的判别 223
16.1.3 评价策略的优劣 223
16.2 非合作关系设定下的多智能体A2C 224
16.2.1 策略网络和价值网络 224
16.2.2 算法推导 225
16.2.3 训练 226
16.2.4 决策 227
16.3 三种架构 227
16.3.1 中心化训练+中心化决策 227
16.3.2 去中心化训练+去中心化决策 228
16.3.3 中心化训练+去中心化决策 229
16.4 连续控制与MADDPG 231
16.4.1 策略网络和价值网络 231
16.4.2 算法推导 232
16.4.3 中心化训练 234
16.4.4 去中心化决策 236
相关文献 237
知识点小结 237
第 17章 注意力机制与多智能体强化学习 238
17.1 自注意力机制 238
17.1.1 自注意力层 239
17.1.2 多头自注意力层 241
17.2 自注意力改进多智能体强化学习 242
17.2.1 不使用自注意力的状态价值网络 242
17.2.2 使用自注意力的状态价值网络 243
17.2.3 使用自注意力的动作价值网络 244
17.2.4 使用自注意力的中心化策略网络 244
17.2.5 总结 245
相关文献 245
知识点小结 245
习题 246
第五部分 应用与展望
第 18章 AlphaGo与蒙特卡洛树搜索 248
18.1 强化学习眼中的围棋 248
18.2 蒙特卡洛树搜索 250
18.2.1 MCTS的基本思想 250
18.2.2 MCTS的四个步骤 250
18.2.3 MCTS的决策 255
18.3 训练策略网络和价值网络 255
18.3.1 AlphaGo 2016版本的训练 256
18.3.2 AlphaGo Zero版本的训练 258
相关文献 260
知识点小结 260
习题 261
第 19章 现实世界中的应用 262
19.1 神经网络结构搜索 262
19.1.1 *参数和交叉验证 262
19.1.2 强化学习方法 264
19.2 自动生成SQL语句 266
19.3 推荐系统 268
19.4 网约车调度 270
19.4.1 价值学习 271
19.4.2 派单机制 271
19.5 强化学习与监督学习的对比 273
19.5.1 决策是否改变环境 273
19.5.2 当前奖励还是长线回报 274
19.6 制约强化学习落地应用的因素 275
19.6.1 所需的样本数量过大 275
19.6.2 探索阶段代价太大 276
19.6.3 *参数的影响非常大 277
19.6.4 稳定性极差 278
知识点小结 279
附录A 贝尔曼方程 281
附录B 习题答案 283
参考文献 288
定价:129.8
ISBN:9787115600691
作者:王树森,黎彧君,张志华
版次:第1版
出版时间:2022-11
内容提要:
本书基于备受读者推崇的王树森“深度强化学习”系列公开视频课,专门解决“入门深度强化学习难”的问题。 本书的独特之处在于:*,知识精简,剔除一切不*要的概念和公式,学起来轻松;*,内容新颖,聚焦近10年深度强化学习领域的突破,让你一上手*紧跟*。本书系统讲解深度强化学习的原理与实现,但不回避数学公式和各种模型,原创100多幅精美插图,并以全彩印刷展示。简洁清晰的语言+生动形象的图示,助你扫除任何可能的学习障碍!本书内容分为五部分:基础知识、价值学习、策略学习、多智能体强化学习、应用与展望,涉及DQN、A3C、TRPO、DDPG、AlphaGo等。 本书面向深度强化学习入门读者,助你构建完整的知识体系。学完本书,你能够轻松看懂深度强化学习的实现代码、读懂该领域的论文、听懂学术报告,具备进一步自学和深挖的能力。
作者简介:
王树森 现任小红书基础模型团队负责人,从事搜索和推荐算法研发工作。从浙江大学获得计算机学士和博士学位,*读期间获得“微软学者”和“百度奖学金”等多项荣誉。在加入小红书之前,曾任美国加州大学伯克利分校博士后、美国史蒂文斯理工学院助理教授、博导。在机器学习、强化学习、数值计算、分布式计算等方向有多年科研经验,在计算机国际*期刊和会议上发表30多篇论文。 在YouTube、B站开设“深度强化学习”“深度学习”“推荐系统”公开课(ID:Shusen Wang),全网视频播放量100万次。 黎彧君 华为诺亚方舟实验室*研究员,主要从事AutoML相关的研发工作。上海交通大学博士,研究方向为数值优化、强化学习;攻读博士学位期间曾前往普林斯顿大学访问一年。共同翻译出版“花书”《深度学习》。 张志华 北京大学数学科学学院教授。此前先后执教于浙江大学和上海交通大学,任计算机科学教授。主要从事统计学、机器学习与计算机科学领域的研究和教学。曾主讲“统计机器学习”“机器学习导论”“深度学习”“强化学习”,其课程视频广受欢迎。
目录:
序言 i
前言 v
常用符号 xi
第 一部分 基础知识
第 1章 机器学习基础 2
1.1 线性模型 2
1.1.1 线性回归 2
1.1.2 逻辑斯谛回归 4
1.1.3 softmax分类器 7
1.2 神经网络 10
1.2.1 全连接神经网络 10
1.2.2 卷积神经网络 11
1.3 梯度下降和反向传播 12
1.3.1 梯度下降 13
1.3.2 反向传播 14
知识点小结 16
习题 16
第 2章 蒙特卡洛方法 18
2.1 随机变量 18
2.2 蒙特卡洛方法实例 21
2.2.1 例一:近似π值 21
2.2.2 例二:估算阴影部分面积 23
2.2.3 例三:近似定积分 25
2.2.4 例四:近似期望 26
2.2.5 例五:随机梯度 27
知识点小结 29
习题 29
第3章 强化学习基本概念 31
3.1 马尔可夫决策过程 31
3.1.1 状态、动作、奖励 31
3.1.2 状态转移 32
3.2 策略 33
3.3 随机性 35
3.4 回报与折扣回报 37
3.4.1 回报 37
3.4.2 折扣回报 37
3.4.3 回报中的随机性 38
3.4.4 有限期MDP和无限期MDP 39
3.5 价值函数 39
3.5.1 动作价值函数 40
3.5.2 *动作价值函数 40
3.5.3 状态价值函数 41
3.6 实验环境:OpenAI Gym 42
知识点小结 44
习题 44
*部分 价值学习
第4章 DQN与Q学习 48
4.1 DQN 48
4.1.1 概念回顾 48
4.1.2 DQN表达式 49
4.1.3 DQN的梯度 50
4.2 TD算法 50
4.2.1 驾车时间预测示例 50
4.2.2 TD算法的原理 51
4.3 用TD训练DQN 53
4.3.1 算法推导 53
4.3.2 训练流程 55
4.4 Q 学习算法 57
4.4.1 表格形式的Q学习 57
4.4.2 算法推导 57
4.4.3 训练流程 58
4.5 同策略与异策略 59
相关文献 60
知识点小结 61
习题 61
第5章 SARSA算法 63
5.1 表格形式的SARSA 63
5.1.1 算法推导 63
5.1.2 训练流程 64
5.1.3 Q学习与SARSA的对比 65
5.2 神经网络形式的SARSA 66
5.2.1 价值网络 66
5.2.2 算法推导 66
5.2.3 训练流程 67
5.3 多步TD目标 68
5.3.1 算法推导 68
5.3.2 多步TD目标的原理 69
5.3.3 训练流程 70
5.4 蒙特卡洛方法与自举 70
5.4.1 蒙特卡洛方法 71
5.4.2 自举 71
5.4.3 蒙特卡洛方法和自举的对比 72
相关文献 73
知识点小结 73
习题 74
第6章 价值学习*技巧 75
6.1 经验回放 75
6.1.1 经验回放的优点 76
6.1.2 经验回放的局限性 76
6.1.3 优先经验回放 77
6.2 高估问题及解决方法 79
6.2.1 自举导致偏差传播 79
6.2.2 *化导致高估 80
6.2.3 高估的危害 81
6.2.4 使用目标网络 82
6.2.5 双Q学习算法 84
6.2.6 总结 85
6.3 对决网络 86
6.3.1 *优势函数 86
6.3.2 对决网络的结构 87
6.3.3 解决不*性 88
6.3.4 对决网络的实际实现 89
6.4 噪声网络 90
6.4.1 噪声网络的原理 90
6.4.2 噪声DQN 91
6.4.3 训练流程 93
相关文献 94
知识点小结 94
习题 94
第三部分 策略学习
第7章 策略梯度方法 98
7.1 策略网络 98
7.2 策略学习的目标函数 99
7.3 策略梯度定理 101
7.3.1 简化证明 101
7.3.2 严格证明 102
7.3.3 近似策略梯度 106
7.4 REINFORCE 107
7.4.1 简化推导 108
7.4.2 训练流程 108
7.4.3 严格推导 109
7.5 actor-critic 110
7.5.1 价值网络 110
7.5.2 算法推导 111
7.5.3 训练流程 114
7.5.4 用目标网络改进训练 114
相关文献 115
知识点小结 115
习题 116
第8章 带基线的策略梯度方法 117
8.1 策略梯度中的基线 117
8.1.1 基线的引入 117
8.1.2 基线的直观解释 118
8.2 带基线的REINFORCE算法 119
8.2.1 策略网络和价值网络 120
8.2.2 算法推导 121
8.2.3 训练流程 121
8.3 advantage actor-critic 122
8.3.1 算法推导 123
8.3.2 训练流程 125
8.3.3 用目标网络改进训练 126
8.4 证明带基线的策略梯度定理 127
知识点小结 128
习题 128
第9章 策略学习*技巧 129
9.1 置信域策略优化 129
9.1.1 置信域方法 129
9.1.2 策略学习的目标函数 132
9.1.3 算法推导 133
9.1.4 训练流程 135
9.2 策略学习中的熵正则 135
相关文献 138
知识点小结 138
第 10章 连续控制 139
10.1 连续空间的离散化 139
10.2 深度确定性策略梯度 140
10.2.1 策略网络和价值网络 140
10.2.2 算法推导 142
10.3 深入分析DDPG 145
10.3.1 从策略学习的角度看待DDPG 145
10.3.2 从价值学习的角度看待DDPG 146
10.3.3 DDPG的高估问题 147
10.4 双延迟深度确定性策略梯度 148
10.4.1 高估问题的解决方案——目标网络 148
10.4.2 高估问题的解决方案——截断双Q学习 148
10.4.3 其他改进点 149
10.4.4 训练流程 150
10.5 随机高斯策略 151
10.5.1 基本思路 152
10.5.2 随机高斯策略网络 153
10.5.3 策略梯度 154
10.5.4 用REINFORCE学习参数 155
10.5.5 用actor-critic学习参数 155
相关文献 157
知识点小结 157
第 11章 对状态的不完全观测 158
11.1 不完全观测问题 158
11.2 循环神经网络 159
11.3 基于RNN的策略网络 161
相关文献 162
知识点小结 163
习题 163
第 12章 模仿学习 165
12.1 行为克隆 165
12.1.1 连续控制问题 165
12.1.2 离散控制问题 166
12.1.3 行为克隆与强化学习的对比 168
12.2 逆向强化学习 169
12.2.1 IRL的基本设定 169
12.2.2 IRL的基本思想 170
12.2.3 从黑箱策略反推奖励 170
12.2.4 用奖励函数训练策略网络 171
12.3 生成判别模仿学习 171
12.3.1 生成判别网络 172
12.3.2 GAIL的生成器和判别器 175
12.3.3 GAIL的训练 176
相关文献 178
知识点小结 179
第四部分 多智能体强化学习
第 13章 并行计算 182
13.1 并行计算基础 182
13.1.1 并行梯度下降 182
13.1.2 MapReduce 183
13.1.3 用 MapReduce实现并行梯度下降 184
13.1.4 并行计算的代价 187
13.2 同步与异步 188
13.2.1 同步算法 188
13.2.2 异步算法 189
13.2.3 同步梯度下降与异步梯度下降的对比 191
13.3 并行强化学习 191
13.3.1 异步并行双Q学习 191
13.3.2 A3C:异步并行A2C 193
相关文献 195
知识点小结 195
习题 196
第 14章 多智能体系统 197
14.1 常见设定 197
14.2 基本概念 199
14.2.1 专业术语 199
14.2.2 策略网络 200
14.2.3 动作价值函数 200
14.2.4 状态价值函数 201
14.3 实验环境 202
14.3.1 multi-agent particle world 202
14.3.2 StarCraft multi-agent challenge 204
14.3.3 Hanabi Challenge 205
相关文献 206
知识点小结 206
第 15章 完全合作关系设定下的多智能体强化学习 207
15.1 完全合作关系设定下的策略学习 208
15.2 完全合作关系设定下的多智能体A2C 209
15.2.1 策略网络和价值网络 209
15.2.2 训练和决策 211
15.2.3 实现中的难点 212
15.3 三种架构 213
15.3.1 中心化训练+中心化决策 214
15.3.2 去中心化训练+去中心化决策 215
15.3.3 中心化训练+去中心化决策 217
相关文献 219
知识点小结 220
习题 220
第 16章 非合作关系设定下的多智能体强化学习 221
16.1 非合作关系设定下的策略学习 222
16.1.1 非合作关系设定下的目标函数 222
16.1.2 收敛的判别 223
16.1.3 评价策略的优劣 223
16.2 非合作关系设定下的多智能体A2C 224
16.2.1 策略网络和价值网络 224
16.2.2 算法推导 225
16.2.3 训练 226
16.2.4 决策 227
16.3 三种架构 227
16.3.1 中心化训练+中心化决策 227
16.3.2 去中心化训练+去中心化决策 228
16.3.3 中心化训练+去中心化决策 229
16.4 连续控制与MADDPG 231
16.4.1 策略网络和价值网络 231
16.4.2 算法推导 232
16.4.3 中心化训练 234
16.4.4 去中心化决策 236
相关文献 237
知识点小结 237
第 17章 注意力机制与多智能体强化学习 238
17.1 自注意力机制 238
17.1.1 自注意力层 239
17.1.2 多头自注意力层 241
17.2 自注意力改进多智能体强化学习 242
17.2.1 不使用自注意力的状态价值网络 242
17.2.2 使用自注意力的状态价值网络 243
17.2.3 使用自注意力的动作价值网络 244
17.2.4 使用自注意力的中心化策略网络 244
17.2.5 总结 245
相关文献 245
知识点小结 245
习题 246
第五部分 应用与展望
第 18章 AlphaGo与蒙特卡洛树搜索 248
18.1 强化学习眼中的围棋 248
18.2 蒙特卡洛树搜索 250
18.2.1 MCTS的基本思想 250
18.2.2 MCTS的四个步骤 250
18.2.3 MCTS的决策 255
18.3 训练策略网络和价值网络 255
18.3.1 AlphaGo 2016版本的训练 256
18.3.2 AlphaGo Zero版本的训练 258
相关文献 260
知识点小结 260
习题 261
第 19章 现实世界中的应用 262
19.1 神经网络结构搜索 262
19.1.1 *参数和交叉验证 262
19.1.2 强化学习方法 264
19.2 自动生成SQL语句 266
19.3 推荐系统 268
19.4 网约车调度 270
19.4.1 价值学习 271
19.4.2 派单机制 271
19.5 强化学习与监督学习的对比 273
19.5.1 决策是否改变环境 273
19.5.2 当前奖励还是长线回报 274
19.6 制约强化学习落地应用的因素 275
19.6.1 所需的样本数量过大 275
19.6.2 探索阶段代价太大 276
19.6.3 *参数的影响非常大 277
19.6.4 稳定性极差 278
知识点小结 279
附录A 贝尔曼方程 281
附录B 习题答案 283
参考文献 288
- 人民邮电出版社有限公司 (微信公众号认证)
- 人民邮电出版社微店,为您提供最全面,最专业的一站式购书服务
- 扫描二维码,访问我们的微信店铺
- 随时随地的购物、客服咨询、查询订单和物流...









