PyTorch自然语言处理入门与实战 机器学习自然语言处理模型函数优化框架数据集处理 环境搭建权重向量 计算机科学
¥59.90
| 运费: | ¥ 0.00-20.00 |



商品详情
书名:PyTorch自然语言处理入门与实战
定价:79.9
ISBN:9787115595256
作者:孙小文,王薪宇,杨谈
版次:第1版
出版时间:2022-11
内容提要:
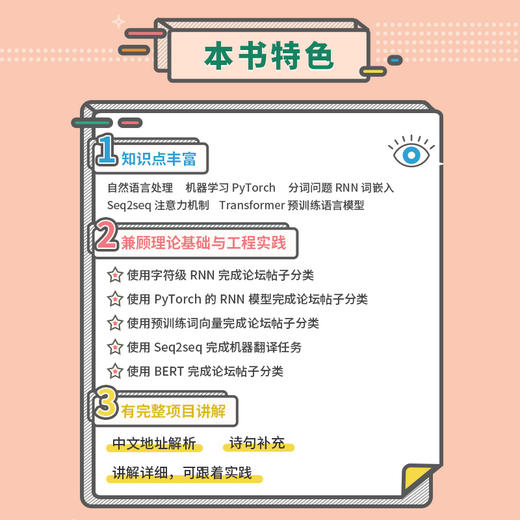
运用PyTorch 探索自然语言处理与机器学习! 这是一本兼顾理论基础和工程实践的入门级教程,基于 PyTorch,揭示自然语言处理的原理,描绘*学术研究脉络,通过实践与项目展现技术与应用的细节,并提供可扩展阅读的论文出处。
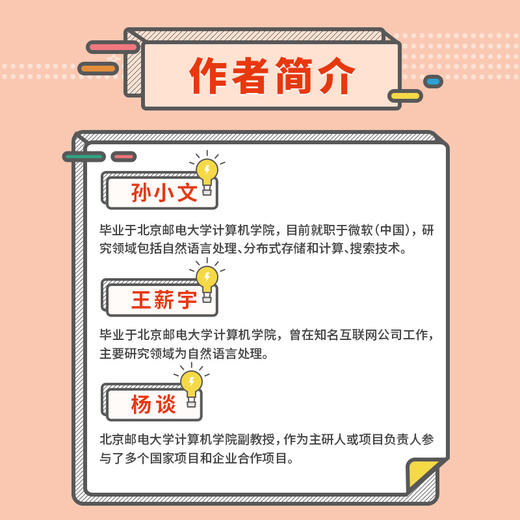
作者简介:
孙小文:毕业于北京邮电大学计算机学院(国家示范性软件学院),目前*职于微软(中国),研究领域包括自然语言处理、分布式存储和计算、搜索技术。 王薪宇:毕业于北京邮电大学计算机学院(国家示范性软件学院),曾在知名互联网公司工作,主要研究领域为自然语言处理。 杨谈:北京邮电大学计算机学院(国家示范性软件学院)副教授,作为主研人或项目负责人参与了多个国家项目和企业合作项目。
目录:
目 录
第 1篇 自然语言处理基础篇
第 1章 自然语言处理概述 2
1.1 什么是自然语言处理 2
1.1.1 定义 2
1.1.2 常用术语 3
1.1.3 自然语言处理的任务 3
1.1.4 自然语言处理的发展历程 4
1.2 自然语言处理中的挑战 5
1.2.1 歧义问题 5
1.2.2 语言的多样性 6
1.2.3 未登录词 6
1.2.4 数据稀疏 6
1.3 自然语言处理中的常用技术 8
1.4 机器学习中的常见问题 10
1.4.1 Batch和Epoch 10
1.4.2 Batch Size的选择 11
1.4.3 数据集不平衡问题 11
1.4.4 预训练模型与数据* 12
1.4.5 通过开源代码学习 12
1.5 小结 13
第 2章 Python自然语言处理基础 14
2.1 搭建环境 14
2.1.1 选择Python版本 14
2.1.2 安装Python 15
2.1.3 使用pip包管理工具和Python虚拟环境 17
2.1.4 使用集成开发环境 18
2.1.5 安装Python自然语言处理常用的库 21
2.2 用Python处理字符串 25
2.2.1 使用str类型 25
2.2.2 使用StringIO类 29
2.3 用Python处理语料 29
2.3.1 从文件读取语料 29
2.3.2 去重 31
2.3.3 停用词 31
2.3.4 编辑距离 31
2.3.5 文本规范化 32
2.3.6 分词 34
2.3.7 词频-逆文本频率 35
2.3.8 One-Hot 编码 35
2.4 Python的一些特性 36
2.4.1 动态的解释型语言 36
2.4.2 跨平台 37
2.4.3 性能问题 37
2.4.4 并行和并发 37
2.5 在Python中调用其他语言 38
2.5.1 通过ctypes调用C/C++代码 38
2.5.2 通过网络接口调用其他语言 40
2.6 小结 41
第 2篇 PyTorch入门篇
第3章 PyTorch介绍 44
3.1 概述 44
3.2 与其他框架的比较 45
3.2.1 TensorFlow 45
3.2.2 PaddlePaddle 45
3.2.3 CNTK 46
3.3 PyTorch环境配置 46
3.3.1 通过pip安装 46
3.3.2 配置GPU环境 47
3.3.3 其他安装方法 48
3.3.4 在PyTorch中查看GPU是否可用 49
3.4 Transformers简介及安装 49
3.5 Apex简介及安装 50
3.6 小结 50
第4章 PyTorch基本使用方法 51
4.1 张量的使用 51
4.1.1 创建张量 51
4.1.2 张量的变换 53
4.1.3 张量的索引 59
4.1.4 张量的运算 59
4.2 使用torch.nn 60
4.3 *函数 63
4.3.1 Sigmoid函数 63
4.3.2 Tanh函数 64
4.3.3 ReLU函数 64
4.3.4 Softmax函数 65
4.3.5 Softmin函数 65
4.3.6 LogSoftmax函数 66
4.4 损失函数 66
4.4.1 0-1损失函数 66
4.4.2 平方损失函数 66
4.4.3 *值损失函数 68
4.4.4 对数损失函数 68
4.5 优化器 69
4.5.1 SGD优化器 69
4.5.2 Adam优化器 70
4.5.3 AdamW优化器 70
4.6 数据加载 70
4.6.1 Dataset 70
4.6.2 DataLoader 71
4.7 使用PyTorch实现逻辑回归 73
4.7.1 生成随机数据 73
4.7.2 数据可视化 73
4.7.3 定义模型 74
4.7.4 训练模型 75
4.8 TorchText 76
4.8.1 安装TorchText 76
4.8.2 Data类 76
4.8.3 Datasets类 78
4.8.4 Vocab 79
4.8.5 utils 80
4.9 使用TensorBoard 81
4.9.1 安装和启动TensorBoard 81
4.9.2 在PyTorch中使用TensorBoard 81
4.10 小结 81
第5章 热身:使用字符级RNN分类帖子 82
5.1 数据与目标 82
5.1.1 数据 82
5.1.2 目标 84
5.2 输入与输出 84
5.2.1 统计数据集中出现的字符数量 85
5.2.2 使用One-Hot编码表示标题数据 85
5.2.3 使用词嵌入表示标题数据 85
5.2.4 输出 86
5.3 字符级RNN 87
5.3.1 定义模型 87
5.3.2 运行模型 87
5.4 数据预处理 89
5.4.1 合并数据并添加标签 90
5.4.2 划分训练集和数据集 90
5.5 训练与评估 90
5.5.1 训练 91
5.5.2 评估 91
5.5.3 训练模型 91
5.6 保存和加载模型 93
5.6.1 仅保存模型参数 93
5.6.2 保存模型与参数 93
5.6.3 保存词表 94
5.7 开发应用 94
5.7.1 给出任意标题的建议分类 94
5.7.2 获取用户输入并返回结果 95
5.7.3 开发Web API和Web界面 96
5.8 小结 97
第3篇 用PyTorch完成自然语言处理任务篇
第6章 分词问题 100
6.1 中文分词 100
6.1.1 中文的语言结构 100
6.1.2 未收录词 101
6.1.3 歧义 101
6.2 分词原理 101
6.2.1 基于词典匹配的分词 101
6.2.2 基于概率进行分词 102
6.2.3 基于机器学习的分词 105
6.3 使用第三方工具分词 106
6.3.1 S-MSRSeg 106
6.3.2 ICTCLAS 107
6.3.3 结巴分词 107
6.3.4 pkuseg 107
6.4 实践 109
6.4.1 对标题分词 109
6.4.2 统计词语数量与模型训练 109
6.4.3 处理用户输入 110
6.5 小结 110
第7章 RNN 111
7.1 RNN的原理 111
7.1.1 原始RNN 111
7.1.2 LSTM 113
7.1.3 GRU 114
7.2 PyTorch中的RNN 115
7.2.1 使用RNN 115
7.2.2 使用LSTM和GRU 116
7.2.3 双向RNN和多层RNN 117
7.3 RNN可以完成的任务 117
7.3.1 输入不定长,输出与输入长度相同 117
7.3.2 输入不定长,输出定长 118
7.3.3 输入定长,输出不定长 118
7.4 实践:使用PyTorch自带的RNN完成帖子分类 118
7.4.1 载入数据 118
7.4.2 定义模型 119
7.4.3 训练模型 119
7.5 小结 121
第8章 词嵌入 122
8.1 概述 122
8.1.1 词表示 122
8.1.2 PyTorch中的词嵌入 124
8.2 Word2vec 124
8.2.1 Word2vec简介 124
8.2.2 CBOW 125
8.2.3 SG 126
8.2.4 在PyTorch中使用Word2vec 126
8.3 GloVe 127
8.3.1 GloVe的原理 127
8.3.2 在PyTorch中使用GloVe预训练词向量 127
8.4 实践:使用预训练词向量完成帖子标题分类 128
8.4.1 获取预训练词向量 128
8.4.2 加载词向量 128
8.4.3 方法一:直接使用预训练词向量 129
8.4.4 方法二:在Embedding层中载入预训练词向量 130
8.5 小结 131
第9章 Seq2seq 132
9.1 概述 132
9.1.1 背景 132
9.1.2 模型结构 133
9.1.3 训练技巧 134
9.1.4 预测技巧 134
9.2 使用PyTorch实现Seq2seq 134
9.2.1 编码器 134
9.2.2 解码器 135
9.2.3 Seq2seq 136
9.2.4 Teacher Forcing 137
9.2.5 Beam Search 138
9.3 实践:使用Seq2seq完成机器翻译任务 138
9.3.1 数据集 138
9.3.2 数据预处理 139
9.3.3 构建训练集和测试集 141
9.3.4 定义模型 143
9.3.5 初始化模型 145
9.3.6 定义优化器和损失函数 146
9.3.7 训练函数和评估函数 146
9.3.8 训练模型 147
9.3.9 测试模型 148
9.4 小结 149
第 10章 注意力机制 150
10.1 注意力机制的起源 150
10.1.1 在计算机视觉中的应用 150
10.1.2 在自然语言处理中的应用 151
10.2 使用注意力机制的视觉循环模型 151
10.2.1 背景 151
10.2.2 实现方法 152
10.3 Seq2seq中的注意力机制 152
10.3.1 背景 152
10.3.2 实现方法 153
10.3.3 工作原理 154
10.4 自注意力机制 155
10.4.1 背景 155
10.4.2 自注意力机制相关的工作 156
10.4.3 实现方法与应用 156
10.5 其他注意力机制 156
10.6 小结 157
第 11章 Transformer 158
11.1 Transformer的背景 158
11.1.1 概述 158
11.1.2 主要技术 159
11.1.3 优势和缺点 159
11.2 基于卷积网络的Seq2seq 159
11.3 Transformer的结构 159
11.3.1 概述 160
11.3.2 Transformer中的自注意力机制 160
11.3.3 Multi-head Attention 161
11.3.4 使用Positional Encoding 162
11.4 Transformer的改进 164
11.5 小结 164
第 12章 预训练语言模型 165
12.1 概述 165
12.1.1 为什么需要预训练 165
12.1.2 预训练模型的工作方式 166
12.1.3 自然语言处理预训练的发展 166
12.2 ELMo 167
12.2.1 特点 167
12.2.2 模型结构 167
12.2.3 预训练过程 168
12.3 GPT 168
12.3.1 特点 168
12.3.2 模型结构 168
12.3.3 下游任务 169
12.3.4 预训练过程 169
12.3.5 GPT-2和GPT-3 169
12.4 BERT 170
12.4.1 背景 171
12.4.2 模型结构 171
12.4.3 预训练 171
12.4.4 RoBERTa和ALBERT 171
12.5 Hugging Face Transformers 171
12.5.1 概述 172
12.5.2 使用Transformers 172
12.5.3 下载预训练模型 173
12.5.4 Tokenizer 173
12.5.5 BERT的参数 175
12.5.6 BERT的使用 176
12.5.7 GPT-2的参数 180
12.5.8 常见错误及其解决方法 181
12.6 其他开源中文预训练模型 181
12.6.1 TAL-EduBERT 181
12.6.2 Albert 182
12.7 实践:使用Hugging Face Transformers中的BERT做帖子标题分类 182
12.7.1 读取数据 182
12.7.2 导入包和设置参数 183
12.7.3 定义Dataset和DataLoader 183
12.7.4 定义评估函数 184
12.7.5 定义模型 185
12.7.6 训练模型 185
12.8 小结 186
第4篇 实战篇
第 13章 项目:中文地址解析 188
13.1 数据集 188
13.1.1 实验目标与数据集介绍 188
13.1.2 载入数据集 190
13.2 词向量 195
13.2.1 查看词向量文件 195
13.2.2 载入词向量 196
13.3 BERT 196
13.3.1 导入包和配置 196
13.3.2 Dataset和DataLoader 198
13.3.3 定义模型 199
13.3.4 训练模型 200
13.3.5 获取预测结果 202
13.4 HTML5演示程序开发 203
13.4.1 项目结构 203
13.4.2 HTML5界面 204
13.4.3 创建前端事件 206
13.4.4 服务器逻辑 207
13.5 小结 211
第 14章 项目:诗句补充 212
14.1 了解chinese-poetry数据集 212
14.1.1 下载chinese-poetry数据集 212
14.1.2 探索chinese-poetry数据集 213
14.2 准备训练数据 214
14.2.1 选择数据源 214
14.2.2 载入内存 214
14.2.3 切分句子 215
14.2.4 统计字频 218
14.2.5 删除低频字所在诗句 220
14.2.6 词到ID的转换 221
14.3 实现基本的LSTM 222
14.3.1 把处理好的数据和词表存入文件 222
14.3.2 切分训练集和测试集 224
14.3.3 Dataset 224
14.3.4 DataLoader 225
14.3.5 创建Dataset和DataLoader对象 226
14.3.6 定义模型 226
14.3.7 测试模型 228
14.3.8 训练模型 228
14.4 根据句子长度分组 229
14.4.1 按照句子长度分割数据集 229
14.4.2 不用考虑填充的DataLoader 230
14.4.3 创建多个DataLoader对象 230
14.4.4 处理等长句子的LSTM 231
14.4.5 评估模型效果 231
14.4.6 训练模型 232
14.5 使用预训练词向量初始化Embedding层 235
14.5.1 根据词向量调整字表 235
14.5.2 载入预训练权重 240
14.5.3 训练模型 240
14.6 使用Transformer完成诗句生成 244
14.6.1 位置编码 245
14.6.2 使用Transformer 245
14.6.3 训练和评估 246
14.7 使用GPT-2完成对诗模型 247
14.7.1 预训练模型 248
14.7.2 评估模型 249
14.7.3 Fine-tuning 252
14.8 开发HTML5演示程序 257
14.8.1 目录结构 257
14.8.2 HTML5界面 257
14.8.3 创建前端事件 259
14.8.4 服务器逻辑 260
14.8.5 检验结果 263
14.9 小结 264
参考文献 265
定价:79.9
ISBN:9787115595256
作者:孙小文,王薪宇,杨谈
版次:第1版
出版时间:2022-11
内容提要:
运用PyTorch 探索自然语言处理与机器学习! 这是一本兼顾理论基础和工程实践的入门级教程,基于 PyTorch,揭示自然语言处理的原理,描绘*学术研究脉络,通过实践与项目展现技术与应用的细节,并提供可扩展阅读的论文出处。
作者简介:
孙小文:毕业于北京邮电大学计算机学院(国家示范性软件学院),目前*职于微软(中国),研究领域包括自然语言处理、分布式存储和计算、搜索技术。 王薪宇:毕业于北京邮电大学计算机学院(国家示范性软件学院),曾在知名互联网公司工作,主要研究领域为自然语言处理。 杨谈:北京邮电大学计算机学院(国家示范性软件学院)副教授,作为主研人或项目负责人参与了多个国家项目和企业合作项目。
目录:
目 录
第 1篇 自然语言处理基础篇
第 1章 自然语言处理概述 2
1.1 什么是自然语言处理 2
1.1.1 定义 2
1.1.2 常用术语 3
1.1.3 自然语言处理的任务 3
1.1.4 自然语言处理的发展历程 4
1.2 自然语言处理中的挑战 5
1.2.1 歧义问题 5
1.2.2 语言的多样性 6
1.2.3 未登录词 6
1.2.4 数据稀疏 6
1.3 自然语言处理中的常用技术 8
1.4 机器学习中的常见问题 10
1.4.1 Batch和Epoch 10
1.4.2 Batch Size的选择 11
1.4.3 数据集不平衡问题 11
1.4.4 预训练模型与数据* 12
1.4.5 通过开源代码学习 12
1.5 小结 13
第 2章 Python自然语言处理基础 14
2.1 搭建环境 14
2.1.1 选择Python版本 14
2.1.2 安装Python 15
2.1.3 使用pip包管理工具和Python虚拟环境 17
2.1.4 使用集成开发环境 18
2.1.5 安装Python自然语言处理常用的库 21
2.2 用Python处理字符串 25
2.2.1 使用str类型 25
2.2.2 使用StringIO类 29
2.3 用Python处理语料 29
2.3.1 从文件读取语料 29
2.3.2 去重 31
2.3.3 停用词 31
2.3.4 编辑距离 31
2.3.5 文本规范化 32
2.3.6 分词 34
2.3.7 词频-逆文本频率 35
2.3.8 One-Hot 编码 35
2.4 Python的一些特性 36
2.4.1 动态的解释型语言 36
2.4.2 跨平台 37
2.4.3 性能问题 37
2.4.4 并行和并发 37
2.5 在Python中调用其他语言 38
2.5.1 通过ctypes调用C/C++代码 38
2.5.2 通过网络接口调用其他语言 40
2.6 小结 41
第 2篇 PyTorch入门篇
第3章 PyTorch介绍 44
3.1 概述 44
3.2 与其他框架的比较 45
3.2.1 TensorFlow 45
3.2.2 PaddlePaddle 45
3.2.3 CNTK 46
3.3 PyTorch环境配置 46
3.3.1 通过pip安装 46
3.3.2 配置GPU环境 47
3.3.3 其他安装方法 48
3.3.4 在PyTorch中查看GPU是否可用 49
3.4 Transformers简介及安装 49
3.5 Apex简介及安装 50
3.6 小结 50
第4章 PyTorch基本使用方法 51
4.1 张量的使用 51
4.1.1 创建张量 51
4.1.2 张量的变换 53
4.1.3 张量的索引 59
4.1.4 张量的运算 59
4.2 使用torch.nn 60
4.3 *函数 63
4.3.1 Sigmoid函数 63
4.3.2 Tanh函数 64
4.3.3 ReLU函数 64
4.3.4 Softmax函数 65
4.3.5 Softmin函数 65
4.3.6 LogSoftmax函数 66
4.4 损失函数 66
4.4.1 0-1损失函数 66
4.4.2 平方损失函数 66
4.4.3 *值损失函数 68
4.4.4 对数损失函数 68
4.5 优化器 69
4.5.1 SGD优化器 69
4.5.2 Adam优化器 70
4.5.3 AdamW优化器 70
4.6 数据加载 70
4.6.1 Dataset 70
4.6.2 DataLoader 71
4.7 使用PyTorch实现逻辑回归 73
4.7.1 生成随机数据 73
4.7.2 数据可视化 73
4.7.3 定义模型 74
4.7.4 训练模型 75
4.8 TorchText 76
4.8.1 安装TorchText 76
4.8.2 Data类 76
4.8.3 Datasets类 78
4.8.4 Vocab 79
4.8.5 utils 80
4.9 使用TensorBoard 81
4.9.1 安装和启动TensorBoard 81
4.9.2 在PyTorch中使用TensorBoard 81
4.10 小结 81
第5章 热身:使用字符级RNN分类帖子 82
5.1 数据与目标 82
5.1.1 数据 82
5.1.2 目标 84
5.2 输入与输出 84
5.2.1 统计数据集中出现的字符数量 85
5.2.2 使用One-Hot编码表示标题数据 85
5.2.3 使用词嵌入表示标题数据 85
5.2.4 输出 86
5.3 字符级RNN 87
5.3.1 定义模型 87
5.3.2 运行模型 87
5.4 数据预处理 89
5.4.1 合并数据并添加标签 90
5.4.2 划分训练集和数据集 90
5.5 训练与评估 90
5.5.1 训练 91
5.5.2 评估 91
5.5.3 训练模型 91
5.6 保存和加载模型 93
5.6.1 仅保存模型参数 93
5.6.2 保存模型与参数 93
5.6.3 保存词表 94
5.7 开发应用 94
5.7.1 给出任意标题的建议分类 94
5.7.2 获取用户输入并返回结果 95
5.7.3 开发Web API和Web界面 96
5.8 小结 97
第3篇 用PyTorch完成自然语言处理任务篇
第6章 分词问题 100
6.1 中文分词 100
6.1.1 中文的语言结构 100
6.1.2 未收录词 101
6.1.3 歧义 101
6.2 分词原理 101
6.2.1 基于词典匹配的分词 101
6.2.2 基于概率进行分词 102
6.2.3 基于机器学习的分词 105
6.3 使用第三方工具分词 106
6.3.1 S-MSRSeg 106
6.3.2 ICTCLAS 107
6.3.3 结巴分词 107
6.3.4 pkuseg 107
6.4 实践 109
6.4.1 对标题分词 109
6.4.2 统计词语数量与模型训练 109
6.4.3 处理用户输入 110
6.5 小结 110
第7章 RNN 111
7.1 RNN的原理 111
7.1.1 原始RNN 111
7.1.2 LSTM 113
7.1.3 GRU 114
7.2 PyTorch中的RNN 115
7.2.1 使用RNN 115
7.2.2 使用LSTM和GRU 116
7.2.3 双向RNN和多层RNN 117
7.3 RNN可以完成的任务 117
7.3.1 输入不定长,输出与输入长度相同 117
7.3.2 输入不定长,输出定长 118
7.3.3 输入定长,输出不定长 118
7.4 实践:使用PyTorch自带的RNN完成帖子分类 118
7.4.1 载入数据 118
7.4.2 定义模型 119
7.4.3 训练模型 119
7.5 小结 121
第8章 词嵌入 122
8.1 概述 122
8.1.1 词表示 122
8.1.2 PyTorch中的词嵌入 124
8.2 Word2vec 124
8.2.1 Word2vec简介 124
8.2.2 CBOW 125
8.2.3 SG 126
8.2.4 在PyTorch中使用Word2vec 126
8.3 GloVe 127
8.3.1 GloVe的原理 127
8.3.2 在PyTorch中使用GloVe预训练词向量 127
8.4 实践:使用预训练词向量完成帖子标题分类 128
8.4.1 获取预训练词向量 128
8.4.2 加载词向量 128
8.4.3 方法一:直接使用预训练词向量 129
8.4.4 方法二:在Embedding层中载入预训练词向量 130
8.5 小结 131
第9章 Seq2seq 132
9.1 概述 132
9.1.1 背景 132
9.1.2 模型结构 133
9.1.3 训练技巧 134
9.1.4 预测技巧 134
9.2 使用PyTorch实现Seq2seq 134
9.2.1 编码器 134
9.2.2 解码器 135
9.2.3 Seq2seq 136
9.2.4 Teacher Forcing 137
9.2.5 Beam Search 138
9.3 实践:使用Seq2seq完成机器翻译任务 138
9.3.1 数据集 138
9.3.2 数据预处理 139
9.3.3 构建训练集和测试集 141
9.3.4 定义模型 143
9.3.5 初始化模型 145
9.3.6 定义优化器和损失函数 146
9.3.7 训练函数和评估函数 146
9.3.8 训练模型 147
9.3.9 测试模型 148
9.4 小结 149
第 10章 注意力机制 150
10.1 注意力机制的起源 150
10.1.1 在计算机视觉中的应用 150
10.1.2 在自然语言处理中的应用 151
10.2 使用注意力机制的视觉循环模型 151
10.2.1 背景 151
10.2.2 实现方法 152
10.3 Seq2seq中的注意力机制 152
10.3.1 背景 152
10.3.2 实现方法 153
10.3.3 工作原理 154
10.4 自注意力机制 155
10.4.1 背景 155
10.4.2 自注意力机制相关的工作 156
10.4.3 实现方法与应用 156
10.5 其他注意力机制 156
10.6 小结 157
第 11章 Transformer 158
11.1 Transformer的背景 158
11.1.1 概述 158
11.1.2 主要技术 159
11.1.3 优势和缺点 159
11.2 基于卷积网络的Seq2seq 159
11.3 Transformer的结构 159
11.3.1 概述 160
11.3.2 Transformer中的自注意力机制 160
11.3.3 Multi-head Attention 161
11.3.4 使用Positional Encoding 162
11.4 Transformer的改进 164
11.5 小结 164
第 12章 预训练语言模型 165
12.1 概述 165
12.1.1 为什么需要预训练 165
12.1.2 预训练模型的工作方式 166
12.1.3 自然语言处理预训练的发展 166
12.2 ELMo 167
12.2.1 特点 167
12.2.2 模型结构 167
12.2.3 预训练过程 168
12.3 GPT 168
12.3.1 特点 168
12.3.2 模型结构 168
12.3.3 下游任务 169
12.3.4 预训练过程 169
12.3.5 GPT-2和GPT-3 169
12.4 BERT 170
12.4.1 背景 171
12.4.2 模型结构 171
12.4.3 预训练 171
12.4.4 RoBERTa和ALBERT 171
12.5 Hugging Face Transformers 171
12.5.1 概述 172
12.5.2 使用Transformers 172
12.5.3 下载预训练模型 173
12.5.4 Tokenizer 173
12.5.5 BERT的参数 175
12.5.6 BERT的使用 176
12.5.7 GPT-2的参数 180
12.5.8 常见错误及其解决方法 181
12.6 其他开源中文预训练模型 181
12.6.1 TAL-EduBERT 181
12.6.2 Albert 182
12.7 实践:使用Hugging Face Transformers中的BERT做帖子标题分类 182
12.7.1 读取数据 182
12.7.2 导入包和设置参数 183
12.7.3 定义Dataset和DataLoader 183
12.7.4 定义评估函数 184
12.7.5 定义模型 185
12.7.6 训练模型 185
12.8 小结 186
第4篇 实战篇
第 13章 项目:中文地址解析 188
13.1 数据集 188
13.1.1 实验目标与数据集介绍 188
13.1.2 载入数据集 190
13.2 词向量 195
13.2.1 查看词向量文件 195
13.2.2 载入词向量 196
13.3 BERT 196
13.3.1 导入包和配置 196
13.3.2 Dataset和DataLoader 198
13.3.3 定义模型 199
13.3.4 训练模型 200
13.3.5 获取预测结果 202
13.4 HTML5演示程序开发 203
13.4.1 项目结构 203
13.4.2 HTML5界面 204
13.4.3 创建前端事件 206
13.4.4 服务器逻辑 207
13.5 小结 211
第 14章 项目:诗句补充 212
14.1 了解chinese-poetry数据集 212
14.1.1 下载chinese-poetry数据集 212
14.1.2 探索chinese-poetry数据集 213
14.2 准备训练数据 214
14.2.1 选择数据源 214
14.2.2 载入内存 214
14.2.3 切分句子 215
14.2.4 统计字频 218
14.2.5 删除低频字所在诗句 220
14.2.6 词到ID的转换 221
14.3 实现基本的LSTM 222
14.3.1 把处理好的数据和词表存入文件 222
14.3.2 切分训练集和测试集 224
14.3.3 Dataset 224
14.3.4 DataLoader 225
14.3.5 创建Dataset和DataLoader对象 226
14.3.6 定义模型 226
14.3.7 测试模型 228
14.3.8 训练模型 228
14.4 根据句子长度分组 229
14.4.1 按照句子长度分割数据集 229
14.4.2 不用考虑填充的DataLoader 230
14.4.3 创建多个DataLoader对象 230
14.4.4 处理等长句子的LSTM 231
14.4.5 评估模型效果 231
14.4.6 训练模型 232
14.5 使用预训练词向量初始化Embedding层 235
14.5.1 根据词向量调整字表 235
14.5.2 载入预训练权重 240
14.5.3 训练模型 240
14.6 使用Transformer完成诗句生成 244
14.6.1 位置编码 245
14.6.2 使用Transformer 245
14.6.3 训练和评估 246
14.7 使用GPT-2完成对诗模型 247
14.7.1 预训练模型 248
14.7.2 评估模型 249
14.7.3 Fine-tuning 252
14.8 开发HTML5演示程序 257
14.8.1 目录结构 257
14.8.2 HTML5界面 257
14.8.3 创建前端事件 259
14.8.4 服务器逻辑 260
14.8.5 检验结果 263
14.9 小结 264
参考文献 265
- 人民邮电出版社有限公司 (微信公众号认证)
- 人民邮电出版社微店,为您提供最全面,最专业的一站式购书服务
- 扫描二维码,访问我们的微信店铺
- 随时随地的购物、客服咨询、查询订单和物流...









