生成式AI入门与AWS实战 GPT大模型应用开发生成式AI教程多模态大模型Agent智能代理langchain编程开发
¥74.90
| 运费: | ¥ 0.00-20.00 |



商品详情
书名:生成式AI入门与AWS实战
定价:99.8
ISBN:9787115644169
作者:[美] 克里斯·弗雷格利(Chris Fregly),[德] 安特耶·巴特(Antje Barth),[美] 舍尔比·艾根布罗德
版次:第1版
出版时间:2024-05
内容提要:
本书是专注于如何在AWS上开发和应用生成式AI的实用指南,旨在为技术*、机器学习实践者、应用*等提供深入了解和应用生成式AI的策略与方法。本书*介绍了生成式AI的概念及其在产品和服务中的应用潜力,然后详细阐述了生成式AI项目的完整生命周期。作者探讨了多种模型类型,如大语言模型和多模态模型,并提供了通过提示工程和上下文学习来优化这些模型的实际技巧。此外,本书讨论了如何使用LoRA技术对模型进行微调,以及如何通过RLHF使模型与人类价值观对齐。书中还介绍了RAG技术,以及如何利用LangChain和ReAct等开发agent。*,本书介绍了如何使用Amazon Bedrock构建基于生成式AI的应用程序。基于该强大的平台,读者可以实现自己的创新想法。 本书适合对生成式AI感兴趣的学生和研究人员、在AWS上开发AI应用程序的软件开发人员和数据科学家、寻求利用AI技术优化业务流程的企业决策者以及对技术趋势保持好奇心的科技爱好者阅读。
作者简介:
Chris Fregly,AWS生成式AI*解决方案架构师,也是O'Reilly图书Data Science on AWS的合著者。 Antje Barth,AWS生成式Al*开发倡导者,也是O'Reilly图书Data Science on AWS的合著者。 Shelbee Eigenbrode,AWS生成式AI*解决方案架构师。她在多个技术领域获得了*过35项专利。
目录:
前言 1
第 1章 生成式AI用例、基础知识和项目生命周期 5
1.1 生成式AI用例和任务 5
1.2 基础模型和模型中心 8
1.3 生成式AI项目生命周期 8
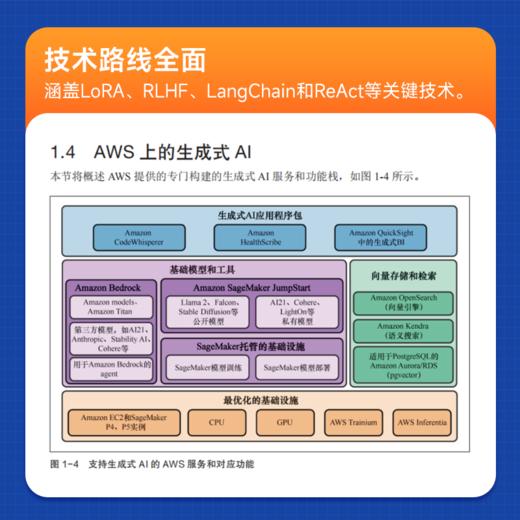
1.4 AWS上的生成式AI 11
1.5 为什么选择基于AWS构建生成式AI 13
1.6 在AWS上构建生成式AI应用程序 14
1.7 小结 16
第 2章 提示工程与上下文学习 17
2.1 提示与补全 17
2.2 token 18
2.3 提示工程 18
2.4 提示结构 19
2.4.1 指令 20
2.4.2 上下文 20
2.5 通过少样本推理进行上下文学习 22
2.5.1 *样本推理 23
2.5.2 单样本推理 23
2.5.3 少样本推理 23
2.5.4 上下文学习出错 24
2.5.5 上下文学习实践 25
2.6 提示工程实践 26
2.7 推理配置参数 31
2.8 小结 36
第3章 大语言基础模型 37
3.1 大语言基础模型简介 37
3.2 分词器 39
3.3 嵌入向量 40
3.4 Transformer 41
3.4.1 输入token上下文窗口 42
3.4.2 嵌入 42
3.4.3 编码器 42
3.4.4 自注意力层 43
3.4.5 解码器 44
3.4.6 Softmax输出 44
3.5 基于Transformer的基础模型的类别 45
3.6 预训练数据集 48
3.7 缩放定律 48
3.8 计算*模型 50
3.9 小结 51
第4章 显存和计算优化 53
4.1 显存容量挑战 53
4.2 数据类型和数值精度 55
4.3 量化 57
4.3.1 fp16 57
4.3.2 bfloat16 59
4.3.3 fp8 60
4.3.4 int8 61
4.4 优化自注意力层 63
4.4.1 FlashAttention 63
4.4.2 分组查询注意力 64
4.5 分布式GPU集群计算 64
4.5.1 分布式数据并行 65
4.5.2 全分片数据并行 66
4.5.3 FSDP与DDP的性能比较 68
4.6 基于AWS的分布式计算 69
4.6.1 通过Amazon SageMaker进行全分片数据并行 69
4.6.2 AWS Neuron SDK与AWS Trainium 71
4.7 小结 72
第5章 微调和评估 73
5.1 指令微调简介 73
5.1.1 Llama 2 74
5.1.2 Falcon 74
5.1.3 FLAN-T5 74
5.2 指令数据集 74
5.2.1 多任务指令数据集 75
5.2.2 FLAN:示例多任务指令数据集 75
5.2.3 提示模板 77
5.2.4 将自定义数据集转换为指令数据集 78
5.3 指令微调的过程 80
5.3.1 Amazon SageMaker Studio 80
5.3.2 Amazon SageMaker JumpStart 81
5.3.3 将Amazon SageMaker Estimator用于Hugging Face 82
5.4 评估 84
5.4.1 评估指标 84
5.4.2 基准测试和数据集 85
5.5 小结 86
第6章 参数*微调 87
6.1 全量微调与PEFT 87
6.2 LoRA和QLoRA 89
6.2.1 LoRA基础 90
6.2.2 秩 91
6.2.3 目标模块和网络层 91
6.2.4 应用LoRA 92
6.2.5 将LoRA适配器与原始模型合并 93
6.2.6 维护独立的LoRA适配器 94
6.2.7 全量微调与 LoRA 性能比较 94
6.2.8 QLoRA 95
6.3 Prompt Tuning和软提示 96
6.4 小结 99
第7章 基于人类反馈的强化学习微调 101
7.1 与人类价值观对齐:有用的、诚实的、无害的 101
7.2 强化学习概述 102
7.3 训练自定义奖励模型 104
7.3.1 通过人机交互收集训练数据集 104
7.3.2 供人类标注者参考的示例指令 105
7.3.3 通过Amazon SageMaker Ground Truth进行人工标注 105
7.3.4 为训练奖励模型准备排序数据 107
7.3.5 训练奖励模型 110
7.4 现有奖励模型:Meta有害性检测器模型 111
7.5 通过人类反馈进行强化学习微调 113
7.5.1 使用奖励模型进行RLHF 113
7.5.2 近端策略优化强化学习算法 114
7.5.3 通过PPO进行RLHF微调 115
7.5.4 缓解奖励破解 117
7.5.5 通过RLHF进行PEFT 118
7.6 评估RLHF微调模型 119
7.6.1 定性评估 119
7.6.2 定量评估 120
7.6.3 载入评估模型 120
7.6.4 定义评估指标聚合函数 120
7.6.5 比较应用RLHF之前和之后的评估指标 121
7.7 小结 122
第8章 模型部署优化 125
8.1 模型推理优化 125
8.1.1 剪枝 126
8.1.2 通过GPTQ进行训练后量化 128
8.1.3 蒸馏 129
8.2 大型模型推理容器 131
8.3 AWS Inferentia:专为推理而打造的硬件 132
8.4 模型更新和部署策略 134
8.4.1 A/B测试 135
8.4.2 影子模型部署 136
8.5 指标和监控 137
8.6 自动伸缩 138
8.6.1 自动伸缩策略 139
8.6.2 定义自动伸缩策略 139
8.7 小结 140
第9章 通过RAG和agent实现基于上下文推理的应用程序 141
9.1 大语言模型的局限性 142
9.1.1 幻觉 142
9.1.2 知识截断 143
9.2 RAG 143
9.2.1 外部知识源 144
9.2.2 RAG工作流 145
9.2.3 文档加载 146
9.2.4 分块 147
9.2.5 检索数据和重新排序 147
9.2.6 提示增强 149
9.3 RAG编排和实现 150
9.3.1 文档加载和分块 151
9.3.2 嵌入向量存储和检索 152
9.3.3 检索链 155
9.3.4 通过MMR进行重新排序 157
9.4 agent 159
9.4.1 ReAct框架 160
9.4.2 PAL框架 162
9.5 生成式AI应用程序 165
9.6 FMOps:实施生成式AI项目生命周期 170
9.6.1 试验注意事项 171
9.6.2 开发注意事项 172
9.6.3 生产部署注意事项 173
9.7 小结 174
第 10章 多模态基础模型 177
10.1 用例 178
10.2 多模态提示工程实践 178
10.3 图像生成和增强 179
10.3.1 图像生成 180
10.3.2 图像编辑和增强 181
10.4 图像补全、图像外部填充和depth-to-image 186
10.4.1 图像补全 186
10.4.2 图像外部填充 187
10.4.3 depth-to-image 188
10.5 图像描述和视觉问答 190
10.5.1 图像描述 191
10.5.2 内容审查 191
10.5.3 视觉问答 192
10.6 模型评估 197
10.6.1 文生图任务 197
10.6.2 图生文任务 199
10.6.3 非语言推理任务 200
10.7 扩散模型架构 201
10.7.1 前向扩散简介 201
10.7.2 反向扩散简介 202
10.7.3 U-Net简介 203
10.8 Stable Diffusion 2架构 204
10.8.1 文本编码器 205
10.8.2 U-Net和扩散过程 206
10.8.3 文本条件控制 207
10.8.4 交叉注意力 208
10.8.5 采样器 208
10.8.6 图像解码器 209
10.9 Stable Diffusion XL架构 209
10.9.1 U-Net和交叉注意力 209
10.9.2 精修模型 209
10.9.3 条件控制 210
10.10 小结 211
第 11章 通过Stable Diffusion进行受控生成和微调 213
11.1 ControlNet 213
11.2 微调 218
11.2.1 DreamBooth 219
11.2.2 DreamBooth与PEFT-LoRA 221
11.2.3 文本反演 222
11.3 通过RLHF进行人类偏好对齐 226
11.4 小结 228
第 12章 Amazon Bedrock:用于生成式AI的托管服务 229
12.1 Bedrock基础模型 229
12.1.1 Amazon Titan基础模型 230
12.1.2 来自Stability AI公司的Stable Diffusion基础模型 230
12.2 Bedrock推理API 230
12.3 大语言模型推理API 232
12.3.1 生成SQL代码 233
12.3.2 文本摘要 233
12.3.3 使用Amazon Bedrock生成嵌入 234
12.4 通过Amazon Bedrock进行微调 237
12.5 通过Amazon Bedrock创建agent 239
12.6 多模态模型 242
12.6.1 文生图 243
12.6.2 图生图 244
12.7 数据隐私和网络* 246
12.8 治理和监控 247
12.9 小结 247
定价:99.8
ISBN:9787115644169
作者:[美] 克里斯·弗雷格利(Chris Fregly),[德] 安特耶·巴特(Antje Barth),[美] 舍尔比·艾根布罗德
版次:第1版
出版时间:2024-05
内容提要:
本书是专注于如何在AWS上开发和应用生成式AI的实用指南,旨在为技术*、机器学习实践者、应用*等提供深入了解和应用生成式AI的策略与方法。本书*介绍了生成式AI的概念及其在产品和服务中的应用潜力,然后详细阐述了生成式AI项目的完整生命周期。作者探讨了多种模型类型,如大语言模型和多模态模型,并提供了通过提示工程和上下文学习来优化这些模型的实际技巧。此外,本书讨论了如何使用LoRA技术对模型进行微调,以及如何通过RLHF使模型与人类价值观对齐。书中还介绍了RAG技术,以及如何利用LangChain和ReAct等开发agent。*,本书介绍了如何使用Amazon Bedrock构建基于生成式AI的应用程序。基于该强大的平台,读者可以实现自己的创新想法。 本书适合对生成式AI感兴趣的学生和研究人员、在AWS上开发AI应用程序的软件开发人员和数据科学家、寻求利用AI技术优化业务流程的企业决策者以及对技术趋势保持好奇心的科技爱好者阅读。
作者简介:
Chris Fregly,AWS生成式AI*解决方案架构师,也是O'Reilly图书Data Science on AWS的合著者。 Antje Barth,AWS生成式Al*开发倡导者,也是O'Reilly图书Data Science on AWS的合著者。 Shelbee Eigenbrode,AWS生成式AI*解决方案架构师。她在多个技术领域获得了*过35项专利。
目录:
前言 1
第 1章 生成式AI用例、基础知识和项目生命周期 5
1.1 生成式AI用例和任务 5
1.2 基础模型和模型中心 8
1.3 生成式AI项目生命周期 8
1.4 AWS上的生成式AI 11
1.5 为什么选择基于AWS构建生成式AI 13
1.6 在AWS上构建生成式AI应用程序 14
1.7 小结 16
第 2章 提示工程与上下文学习 17
2.1 提示与补全 17
2.2 token 18
2.3 提示工程 18
2.4 提示结构 19
2.4.1 指令 20
2.4.2 上下文 20
2.5 通过少样本推理进行上下文学习 22
2.5.1 *样本推理 23
2.5.2 单样本推理 23
2.5.3 少样本推理 23
2.5.4 上下文学习出错 24
2.5.5 上下文学习实践 25
2.6 提示工程实践 26
2.7 推理配置参数 31
2.8 小结 36
第3章 大语言基础模型 37
3.1 大语言基础模型简介 37
3.2 分词器 39
3.3 嵌入向量 40
3.4 Transformer 41
3.4.1 输入token上下文窗口 42
3.4.2 嵌入 42
3.4.3 编码器 42
3.4.4 自注意力层 43
3.4.5 解码器 44
3.4.6 Softmax输出 44
3.5 基于Transformer的基础模型的类别 45
3.6 预训练数据集 48
3.7 缩放定律 48
3.8 计算*模型 50
3.9 小结 51
第4章 显存和计算优化 53
4.1 显存容量挑战 53
4.2 数据类型和数值精度 55
4.3 量化 57
4.3.1 fp16 57
4.3.2 bfloat16 59
4.3.3 fp8 60
4.3.4 int8 61
4.4 优化自注意力层 63
4.4.1 FlashAttention 63
4.4.2 分组查询注意力 64
4.5 分布式GPU集群计算 64
4.5.1 分布式数据并行 65
4.5.2 全分片数据并行 66
4.5.3 FSDP与DDP的性能比较 68
4.6 基于AWS的分布式计算 69
4.6.1 通过Amazon SageMaker进行全分片数据并行 69
4.6.2 AWS Neuron SDK与AWS Trainium 71
4.7 小结 72
第5章 微调和评估 73
5.1 指令微调简介 73
5.1.1 Llama 2 74
5.1.2 Falcon 74
5.1.3 FLAN-T5 74
5.2 指令数据集 74
5.2.1 多任务指令数据集 75
5.2.2 FLAN:示例多任务指令数据集 75
5.2.3 提示模板 77
5.2.4 将自定义数据集转换为指令数据集 78
5.3 指令微调的过程 80
5.3.1 Amazon SageMaker Studio 80
5.3.2 Amazon SageMaker JumpStart 81
5.3.3 将Amazon SageMaker Estimator用于Hugging Face 82
5.4 评估 84
5.4.1 评估指标 84
5.4.2 基准测试和数据集 85
5.5 小结 86
第6章 参数*微调 87
6.1 全量微调与PEFT 87
6.2 LoRA和QLoRA 89
6.2.1 LoRA基础 90
6.2.2 秩 91
6.2.3 目标模块和网络层 91
6.2.4 应用LoRA 92
6.2.5 将LoRA适配器与原始模型合并 93
6.2.6 维护独立的LoRA适配器 94
6.2.7 全量微调与 LoRA 性能比较 94
6.2.8 QLoRA 95
6.3 Prompt Tuning和软提示 96
6.4 小结 99
第7章 基于人类反馈的强化学习微调 101
7.1 与人类价值观对齐:有用的、诚实的、无害的 101
7.2 强化学习概述 102
7.3 训练自定义奖励模型 104
7.3.1 通过人机交互收集训练数据集 104
7.3.2 供人类标注者参考的示例指令 105
7.3.3 通过Amazon SageMaker Ground Truth进行人工标注 105
7.3.4 为训练奖励模型准备排序数据 107
7.3.5 训练奖励模型 110
7.4 现有奖励模型:Meta有害性检测器模型 111
7.5 通过人类反馈进行强化学习微调 113
7.5.1 使用奖励模型进行RLHF 113
7.5.2 近端策略优化强化学习算法 114
7.5.3 通过PPO进行RLHF微调 115
7.5.4 缓解奖励破解 117
7.5.5 通过RLHF进行PEFT 118
7.6 评估RLHF微调模型 119
7.6.1 定性评估 119
7.6.2 定量评估 120
7.6.3 载入评估模型 120
7.6.4 定义评估指标聚合函数 120
7.6.5 比较应用RLHF之前和之后的评估指标 121
7.7 小结 122
第8章 模型部署优化 125
8.1 模型推理优化 125
8.1.1 剪枝 126
8.1.2 通过GPTQ进行训练后量化 128
8.1.3 蒸馏 129
8.2 大型模型推理容器 131
8.3 AWS Inferentia:专为推理而打造的硬件 132
8.4 模型更新和部署策略 134
8.4.1 A/B测试 135
8.4.2 影子模型部署 136
8.5 指标和监控 137
8.6 自动伸缩 138
8.6.1 自动伸缩策略 139
8.6.2 定义自动伸缩策略 139
8.7 小结 140
第9章 通过RAG和agent实现基于上下文推理的应用程序 141
9.1 大语言模型的局限性 142
9.1.1 幻觉 142
9.1.2 知识截断 143
9.2 RAG 143
9.2.1 外部知识源 144
9.2.2 RAG工作流 145
9.2.3 文档加载 146
9.2.4 分块 147
9.2.5 检索数据和重新排序 147
9.2.6 提示增强 149
9.3 RAG编排和实现 150
9.3.1 文档加载和分块 151
9.3.2 嵌入向量存储和检索 152
9.3.3 检索链 155
9.3.4 通过MMR进行重新排序 157
9.4 agent 159
9.4.1 ReAct框架 160
9.4.2 PAL框架 162
9.5 生成式AI应用程序 165
9.6 FMOps:实施生成式AI项目生命周期 170
9.6.1 试验注意事项 171
9.6.2 开发注意事项 172
9.6.3 生产部署注意事项 173
9.7 小结 174
第 10章 多模态基础模型 177
10.1 用例 178
10.2 多模态提示工程实践 178
10.3 图像生成和增强 179
10.3.1 图像生成 180
10.3.2 图像编辑和增强 181
10.4 图像补全、图像外部填充和depth-to-image 186
10.4.1 图像补全 186
10.4.2 图像外部填充 187
10.4.3 depth-to-image 188
10.5 图像描述和视觉问答 190
10.5.1 图像描述 191
10.5.2 内容审查 191
10.5.3 视觉问答 192
10.6 模型评估 197
10.6.1 文生图任务 197
10.6.2 图生文任务 199
10.6.3 非语言推理任务 200
10.7 扩散模型架构 201
10.7.1 前向扩散简介 201
10.7.2 反向扩散简介 202
10.7.3 U-Net简介 203
10.8 Stable Diffusion 2架构 204
10.8.1 文本编码器 205
10.8.2 U-Net和扩散过程 206
10.8.3 文本条件控制 207
10.8.4 交叉注意力 208
10.8.5 采样器 208
10.8.6 图像解码器 209
10.9 Stable Diffusion XL架构 209
10.9.1 U-Net和交叉注意力 209
10.9.2 精修模型 209
10.9.3 条件控制 210
10.10 小结 211
第 11章 通过Stable Diffusion进行受控生成和微调 213
11.1 ControlNet 213
11.2 微调 218
11.2.1 DreamBooth 219
11.2.2 DreamBooth与PEFT-LoRA 221
11.2.3 文本反演 222
11.3 通过RLHF进行人类偏好对齐 226
11.4 小结 228
第 12章 Amazon Bedrock:用于生成式AI的托管服务 229
12.1 Bedrock基础模型 229
12.1.1 Amazon Titan基础模型 230
12.1.2 来自Stability AI公司的Stable Diffusion基础模型 230
12.2 Bedrock推理API 230
12.3 大语言模型推理API 232
12.3.1 生成SQL代码 233
12.3.2 文本摘要 233
12.3.3 使用Amazon Bedrock生成嵌入 234
12.4 通过Amazon Bedrock进行微调 237
12.5 通过Amazon Bedrock创建agent 239
12.6 多模态模型 242
12.6.1 文生图 243
12.6.2 图生图 244
12.7 数据隐私和网络* 246
12.8 治理和监控 247
12.9 小结 247
- 人民邮电出版社有限公司 (微信公众号认证)
- 人民邮电出版社微店,为您提供最全面,最专业的一站式购书服务
- 扫描二维码,访问我们的微信店铺
- 随时随地的购物、客服咨询、查询订单和物流...









